-
JDBC란? (feat. 데이터베이스 커넥션 풀링)Java 2021. 10. 24. 12:12반응형
JDBC(Java Database Connectivity)는 RDBMS에 접근하기 위한 프로그래밍 인터페이스입니다. JDBC의 실행은 대부분 SQL을 데이터베이스 서버에 전송하고 수행하는 것들인데요.
이번 글에서는 JDBC를 중심으로 아래와 관련된 사항들을 알아보겠습니다:
- JDBC 기초
- JDBC 버젼 발전과정
- JDBC 드라이버 타입
JDBC 기초
JDBC는 SQL 문장을 처리하는 엔진에 대한 Call-Level Interface(CLI)에 기반해 있습니다. 좀 더 구체적으로는, JDBC는 SQL92 언어 문법 스탠다드를 따르는 X/Open SQL CLI(X/Open은 국제 규격 조직)를 사용하는데요. 아래 이미지는 어떻게 SQL CLI와 JDBC가 내부적으로 동작하는지 보여줍니다:
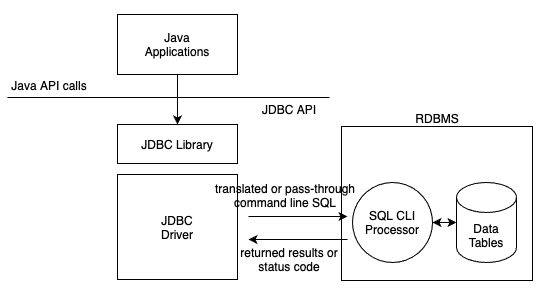
Image from Author inspired by [1] 위 이미지에서 JDBC 엔진은 SQL 쿼리 문장을 원격의 SQL 처리 엔진에 제출합니다. 이후 SQL 처리 엔진은 result set이라고 불리는 데이터 세트를 쿼리의 결과물로 리턴해줍니다. Result set은 보통 0개 이상의 데이터 rows입니다.
그러므로, JDBC 연산을 아래와 같은 형태로 디자인 되었습니다:
- JDBC API 콜을 받아서 SQL 쿼리로 변환함
- 쿼리를 RDBMS의 SQL 처리 엔진에 제출함
- 쿼리로부터 리턴받은 result set을 꺼내어 Java로 접근 가능한 데이터 구조로 변환함
모든 SQL 문장이 result set을 리턴하는 것은 아닙니다. 쿼리 수행이 성공적이지 않은 경우에, 리턴받은 result set은 빈 값이 됩니다.또한, 테이블 생성, 데이터 업데이트, 데이터 삭제 등에 해당되는 SQL 문장들은 result set을 리턴하지 않습니다.
JDBC 프로그래밍 상에서, 개발자들은 주로 아래와 같은 단계를 수행합니다:
- 원격의 데이터베이스 서버의 커넥션을 득함
- 실행을 위해 SQL 문장을 생성하고 준비함
- SQL 문장을 실행함
- result set이 존재하면 리턴받아서 추가적인 작업 수행
- 원격 데이터베이스에서 연결 끊기
JDBC 버젼 발전과정
JDBC의 초기에, 대부분의 Java 개발자는 JDBC 1 스탠다드로 코딩을 진행하였습니다. 이 스탠다드에서, RDBMS로 커넥션을 생성하기 위해 필요한 모든 코드는 개발자에 의해 작성되었습니다. JDBC 드라이버를 선택하고 활성화하는 코드까지도 개발자가 작성하여야 하였습니다.
코딩하기에 간단하고 명료하긴 하였지만, 이러한 방식은 사용될 드라이버는 개발자에 의해 하드코딩되고, 커넥션을 얻기 위한 코드가 특정 벤더에서 제공하는 RDBMS로만 작동된다는 점이 문제였습니다.
JDBC 2가 등장하면서 이러한 제한은 조금씩 개선되었는데요. JDBC 2는 데이터 소스(data source)라는 개념을 도입하였습니다. 이 개념은 커넥션 생성 시에 사용할 JDBC 드라이버를 간접적으로 설정할 수 있게 해주었습니다. 이제 개발자들은 코드 상의 데이터 소스에서 커넥션을 득하고, 같은 JDBC 코드가 벤더가 제공하는 드라이버와 연동할 수 있게 되었습니다. 필요하다면 관리자는 코드 변경 없이 단순히 다른 데이터 소스를 설정하여서 데이터베이스 벤더를 변경할 수 있었습니다. 데이터 소스의 선택과 설정은 이렇게 개발자로부터 관리자로 넘어가게 되었습니다.
웹 애플리케이션이 점점 복잡해져감에 따라서, 데이터베이스 커넥션에 대한 고성능의 동시적인(concurrent) 접근에 대한 요구가 점점 늘어나게 되었습니다. 데이터베이스 커넥션을 유지하고 공유하기 위해 개발자가 작성한 코드는 매우 복잡하고 에러가 발생하기 쉬웠는데요. 이러한 코드는 유틸리티적인 요소가 있어서 모든 애플리케이션에서 사용될 수 있었고, 그렇기에 JDBC 2가 개선하고자 하는 또 다른 방향성 중에 하나였습니다.
JDBC 2에서의 데이터 소스와 커넥션 풀을 도입한 것이 RDBMS 개발자에게 새로운 가능성을 열어준 반면에, 이러한 기능들이 사용되어야만하는 스탠다드를 명시화하는 데에는 부족함이 있었습니다. 그 결과 많은 아키텍쳐 관점의 이슈는 JDBC 드라이버 작성자가 해결해야할 부분으로 남겨져 있었습니다.
더욱이, J2EE의 빠른 고도화는 전체적인 아키텍쳐 구조를 점점 굳혀갔습니다. J2EE 스택 전반에 있는 리소스 어댑터 모델 유사하게 EIS(Enterprise Information System) 시스템에 적용되어 갔습니다. 아키텍쳐적으로, JDBC 커넥션은 EIS으로 간주되는 외부/레거시 시스템에 대한 커넥션입니다. J2EE 아키텍쳐에서 이러한 커넥션은 잘 정의된 커넥터 아키텍쳐를 통해서 관리되어야만 했습니다. 그리고 이 부분은 J2EE Connector Architecture(JCA)가 담당하고 있는 부분이었습니다.
이 아키텍쳐에서, J2EE 소프트웨어 컴포넌트는 EIS 리소스에 잘 정의된 인터페이스 세트와 리소스 어댑터를 통해 접근하였습니다. 이러한 인터페이스들은 커넥션 관리, 트랜잭션 관리, 보안 부분에서 엄격하게 정의된 계약을 강제하였습니다. JDBC 스탠다드의 진화는 그렇기에 이러한 새로운 JCA 아키텍쳐로 점점 이관해왔습니다.
이러한 이관의 첫 번째 단계는 애플리케이션 로직과 특정한 EIS 리소스 간의 직접적인 커플링을 떼어내는 것이었습니다. 이 부분은 중간매개체의 간접적인 룩업 메커니즘을 통해 이뤄질 수 있었습니다. JNDI는 Java 기반의 스탠다드로 이러한 목적을 제공해주었습니다. JDBC 3는 이러한 이관을 고려하여 디자인된 첫 번째 버젼이었습니다.
JDBC 3은 2-티어, 3-티어 모델 등 JDBC가 실행될 수 있는 여러 아키텍쳐를 명확하게 명시한 첫 번째 명세(specification)였습니다. 3-티어 모델은 애플리케이션 서버 모델과 상응하고 J2EE 애플리케이션이 선호하는 모델이었습니다.
또한, JDBC 명세는 JNDI를 데이터 소스를 얻기 위하여 사용되는 적절한 방식으로 공식화하는 동시에 JDBC 1, 2 드라이버와 수행 모델을 통합하려고 시도하였습니다. 또한, 커넥션 풀링을 애플리케이션 서버나 서블릿 컨테이너의 추가적인 서비스로 공식화하였습니다.
JDBC 버젼에 상관 없이, JDBC 드라이버는 여전히 JDBC 커맨드를 다른 서버들에 연결하기 위한 native 커맨드로 번역해야만 하였습니다. 아래에서는 그러한 JDBC 드라이버의 여러 타입을 살펴보겠습니다.
JDBC 드라이버 타입
JDBC 드라이버 타입은 4가지 종류가 존재합니다.
타입 1
가장 primitive한 JDBC 드라이버로 본질적으로 데이터 접근 어댑터에 해당됩니다. 이 타입은 다른 데이터 접근 메커니즘(ODBC 등)을 JDBC로 adapt합니다. 이러한 드라이버는 동작하기 위해서 완전히 다른 접근 메커니즘에 의존하며 그렇기에 관리유지 비용이 2배로 들게 됩니다. 이러한 드라이버는 또한 보통 하드웨어/운영체제 특정하여서 non-portable합니다.
타입 2
이러한 드라이버는 일부는 Java로, 일부는 native 데이터 접근 언어(주로 C나 C++)로 작성되었습니다. Java가 아닌 부분은 이러한 코드의 portability와 플랫폼 이관 가능성을 제한합니다. 타입 1에서의 관리유지 부담이 여전히 존재합니다.
타입 3
이 타입의 드라이버는 클라이언트 쪽은 pure Java 드라이버로 Java의 portability 이점을 제공합니다. 그러나, 외부에서 실행되는 미들웨어에 의존합니다. 클라이언트 코드는 미들웨어 엔진과 통신하고 엔진은 다른 타입의 데이터베이스와 통신합니다. 관리유지비용은 다소 감소했으나, 아직 남아있습니다.
타입 4
100% Java로 RDBMS가 지원하는 네트워크 프로토콜로 직접 통신합니다. 이 결과 성능도 좋고 portable한 코드를 제공합니다. 관리유지 비용도 상당히 줄어들게 됩니다 (오직 드라이버만 업데이트 하면 되기에).
데이터베이스 커넥션 풀링
하나의 웹 애플리케이션이 원격의 RDBMS를 접근할 때, 그 애플리케이션은 JDBC 커넥션을 통해 접근을 수행합니다. 보통 물리적 JDBC 커넥션이 클라이언트와 RDBMS 서버 간에 TCP/IP 커넥션을 통해 형성되는데요. 그러한 커넥션을 생성하는 것은 CPU, Memory, 시간이 많이 소요되는 작업입니다. 그러한 커넥션 생성은 소프트웨어의 여러 레이어와 네트워크 데이터의 전송과 수신을 포함합니다. 보통 물리적 데이터베이스 커넥션은 생성하기까지 몇 초 정도 필요합니다. 간단한 데이터베이스 쿼리를 하나 실행하는 것은 수 밀리세컨초가 소요되는데요. 그렇기에 쿼리 간에 커넥션 생성과 커넥션 종료를 최소화하는 것이 중요합니다.
모던 웹 애플리케이션은 JSP나 서블릿으로 구성되어 매 HTTP 요청마다 데이터베이스에서의 데이터를 필요로 합니다. 부하가 있는 서버에서 실제 커넥션을 매번 생성하고 종료하고 재생성하는 것은 웹 애플리케이션 성능을 매우 저하시킵니다.
고성능에 확장성 있는 웹 애플리케이션을 생성하기 위해서, JDBC 벤더와 애플리케이션은 상품에 데이터베이스 커넥션 풀링을 결합하였습니다.
커넥션 풀링은 시스템이 시작될 때에 물리적 커넥션들의 풀을 생성하여 '비싼' 세션 생성 시간을 줄여줍니다. 애플리케이션이 커넥션을 필요로 하면, 이 풀의 여러 커넥션들 중 하나가 제공됩니다. 보통, 애플리케이션이 커넥션 사용을 끝낼 때 커넥션이 종료됩니다. 그러나, 논리적 커넥션의 경우에는 연관된 물리적 커넥션은 단지 풀로 리턴되고 다음 애플리케이션의 요청을 기다립니다:

Image from Author inspired by [1] 풀 매니저(Pool manager)는 초기의 물리적 커넥션을 생성하고, 웹 애플리케이션에 논리적 커넥션 형태로 물리적 커넥션의 분배를 관리하고, 종료된 논리적 커넥션을 풀로 리턴하고, 발생하는 에러와 예외 처리를 담당합니다. 논리적 커넥션을 종료하는 것은 실제로 물리적 커넥션을 종료하는 것이 아니라, 물리적 커넥션을 풀로 리턴하게 됩니다. 풀 매니저 기능은 아래 3가지 소스 중에 하나에서 제공하게 됩니다:
- 애플리케이션 서버(톰캣 등)
- 써드파티 풀 매니저 소프트웨어 벤더
- JDBC 드라이버 벤더
Reference
[1] Professional Apache Tomcat 5
[2] https://www.geeksforgeeks.org/jdbc-drivers/
[3] Expert Oracle JDBC Programming
반응형'Java' 카테고리의 다른 글
Spring JPA - Maria DB 트랜잭션 로컬 테스트 (0) 2025.01.14 코틀린, 스프링 기반 마이크로서비스 개발을 위해 읽은 책들 (0) 2022.03.11 Kotlin Coroutines for Backend (0) 2022.02.21 Kotlin Inline modifier의 장점 (0) 2022.01.02 Spring Framework란? (0) 2021.09.10 서블릿의 세션 관리 (Servlet Session Management) (0) 2021.02.21 아파치 톰캣 내부구조 (Apache Tomcat Internals) (0) 2021.02.17 서블릿(Servlet)의 구조와 접근방식 (feat. CGI) (0) 2021.02.16