-
해시 알고리즘 특징SE General 2021. 9. 27. 11:03반응형
해시 알고리즘은 String 데이터를 고정된 길이의 숫자형 String 결과물로 변환해주는 함수입니다. 이 결과물 String은 보통 원본 데이터보다 길이가 훨씬 짧은데요. 이렇게 해시 함수가 리턴한 값은 해시 값(hash values), 해시 코드, digests, hashes 등의 이름으로 불립니다.
해시 함수는 대부분의 언어에 기초 자료형으로 쓰이는 해시 테이블에 중심적인 역할을 합니다. 그 외에도 checksums, check digits, 핑거프린팅, lossy compression, randomization 함수, 에러 체킹 코드, ciphers 등에 사용됩니다.
이 글에서는 아래와 같은 사항들을 알아보겠습니다:
- 해시 함수의 기본적인 사항들
- 해시 함수가 쓰이는 곳
- 해시 함수의 일반적인 특징들
해시 함수의 기본적인 사항들
해시 함수는 입력값을 키로 받아서 데이터 또는 레코드와 연결하거나 데이터 저장 위치를 식별하는 데에 사용합니다. 키는 보통 integer와 같이 고정된 길이거나 이름과 같이 변동 길이입니다. 몇몇의 경우에는 키는 데이터 그 자체이기도 합니다. 결과물은 해시 코드로 데이터를 가진 해시 테이블을 인덱싱하는 등에 사용됩니다.
해시 함수는 아래 3가지 기능을 수행해야 합니다:
- 키를 단어들이나 ADD 또는 XOR과 같은 parity-preserving 연산자를 사용해 folding하고, 변동 길이의 키를 고정 길이의 값으로 변환함
- 키의 비트를 섞어서 결과물 값이 키 공간에 고르게 분산될 수 있도록 함
- 키 값을 테이블 크기보다 작거나 같은 것으로 매핑함
동시에 좋은 해시 함수는 1) 빠르게 컴퓨팅 가능해야하고, 2) 결과물 값의 중복(collisions)을 최소화해야 합니다.
해시 함수가 쓰이는 곳
해시 테이블
해시 함수는 해시 테이블에서 사용되며, 해시 테이블은 데이터를 저장하고 꺼내는 데 사용됩니다. 해시 함수는 각 키를 해시 코드로 변환하고, 해시 코드는 해시 테이블의 인덱스로 사용됩니다. 하나의 아이템이 테이블에 추가될 때, 해시 코드는 보통 빈 슬롯의 인덱스로 이 경우 아이템은 테이블의 해당 인덱스 위치에 추가됩니다. 만약 해시 코드 인덱스가 이미 채워진 슬롯을 가르키는 경우에 어떠한 형태의 collision 해결이 필요합니다.
이러한 collision resolution의 방식은 해시 테이블 구조에 따라 다르며 Chaining, Open Addressing(linear probing, quadratic probing, double hashing) 등의 방식이 존재합니다.
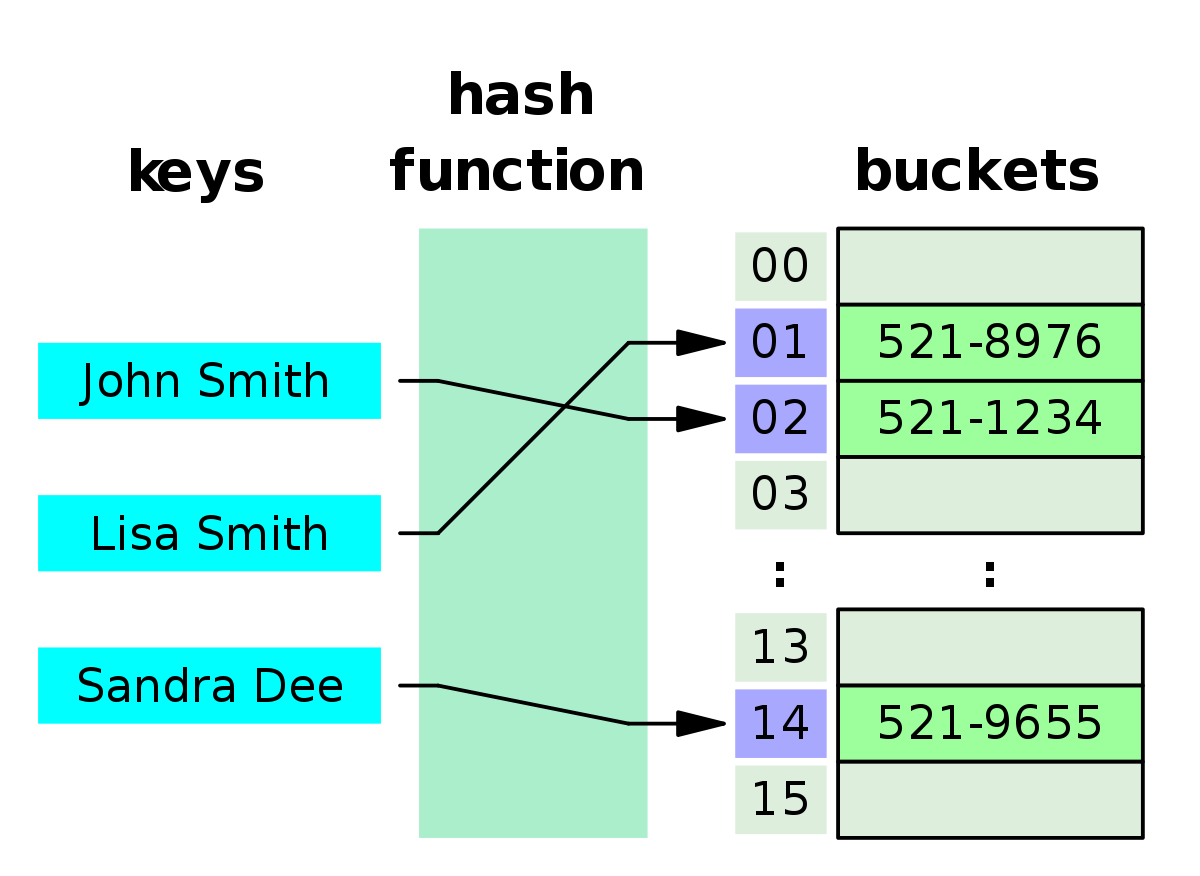
Hash Table - [3] 이러한 해시 테이블은 associative array나 dynamic set에 사용됩니다.
특별한 사용례들
해시 함수는 대용량 데이터셋을 위한 캐시를 만들 때에도 사용됩니다. 캐시는 보통 해시 테이블보다 간단한데, 그 이유는 collision이 충돌하는 2개의 아이템 중 오래된 아이템을 버리거나 덮어쓰는 방법으로 해결 가능하기 때문입니다.
또한, 해시 함수는 Bloom filter의 핵심 요소입니다.
특별한 케이스로 geometric hashing이 존재하는데, 이 함수의 모든 입력값들은 metric space의 일종으로 해시 함수는 공간을 '셀'로 나누는 파티셔닝을 수행하는 것으로 해석될 수 있습니다.
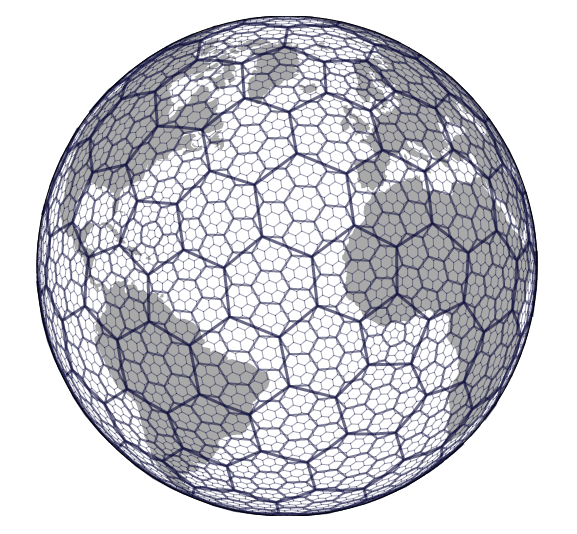
Uber's h3 - [4] 해시 함수의 일반적인 특징들
균일성
좋은 해시 함수는 예상되는 입력값을 가능한 고르게 결과물 범위에 매핑해야 합니다. 즉, 결과물 범위의 모든 해시 값은 대략 같은 확률로 발생해야만 합니다. 이러한 조건의 이유는 해싱 기반의 방법들의 비용이 collision 수가 증가하며 빠르게 올라가기 때문입니다.
이러한 기준은 값이 균일하게 분산되기를 필요로 하며, 어떠한 점에서도 랜덤을 요하지는 않습니다. 그렇기에 좋은 랜더마이징 함수는 일반적으로 좋은 해시 함수이나, 반대는 아닙니다.
해시 테이블에서 일반적으로 m개의 레코드가 n개의 슬롯을 가진 테이블로 해싱된다고 할 때, m/n 레코드 이상의 레코드를 가진 버킷은 존재하기가 어렵습니다. 만약 m이 n보다 작다면 매우 적은 수의 버킷만이 1개 이상의 레코드를 가지게 됩니다. 그러나 언제든 적은 수의 collision은 거의 피하기에 불가능합니다 [5].
키가 미리 알려져서 키 세트가 정적인 특별한 경우에, 완벽한 균일성을 이루는 해시 함수를 찾을 수 있습니다. 그러한 해시 함수는 perfect [6]하다고 정의되는데요. 하지만 그러한 함수를 알고리즘적으로 만들기는 현재 불가능하고, 매우 적은 수의 키 세트에 대한 perfect 해시 함수를 찾는 것도 실질적으로 매우 어렵습니다. 그러한 것을 찾는다고 해도 컴퓨팅적으로 매우 복잡하고 Universal 해시 함수 [7]와 같이 적은 수의 collision으로 좋은 확률적 특징을 지닌 것과 비교할 때 성능에서 아주 조금의 이득을 제공합니다.
테스팅과 측정
해시 함수를 테스트할 때에, 해시값 분산의 균일성을 평가하기 위해 chi-squared 테스트를 사용할 수 있습니다. 이 테스트는 적합도 측정방법으로, 아이템의 예상되는 분산 대 실제 분산을 나타냅니다:
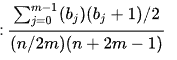
Image from [1] n은 키의 갯수이고, m은 버킷의 갯수, b(j)는 버킷 j에 있는 아이템 수입니다.
값이 신뢰구간인 (0.95 ~ 1.05)에 해당된다면 해시 함수가 예상된 균일한 분산을 보여줌을 나타냅니다.
해시 함수는 적용되었을 때에 더 균일한 분산을 가지도록하는 기술적 특성을 가지기도 합니다. 그 중 하나는 strict avalanche criterion으로 하나의 인풋 비트가 변경되었을 때에 각각의 아웃풋 비트가 50% 확률로 변하는 것입니다. 이 특성은 선택된 키 스페이스가 대부분 유사한 것으로 구성되어 있을 수 있기 때문입니다.
효율성
데이터 저장과 추출 애플리케이션에서, 해시 함수의 사용은 검색 시간과 데이터 저장 공간 간의 트레이드오프입니다. 검색 시간이 unbounded라면, 키-값으로 인덱스 가능하며 랜덤하게 접근 가능한 구조는 매우 크고, 매우 sparse하지만 매우 빠릅니다. 해시 함수는 매우 큰 키 스페이스를 한정된 시간 안에 검색할 수 있을 정도의 저장 공간에 매핑하는 것을 키 숫자에 상관없이 제한적인 시간 안에 처리합니다. 대부분의 애플리케이션에서, 해시 함수는 최소 지연 속도와 최소 instruction 수에 맞게 컴퓨팅 가능해야 합니다.
해시 함수의 컴퓨팅적인 복잡성은 instruction 수와 각 instruction의 지연속도에 따라 변합니다. bitwise 처리, multiplicative 처리, division-based methods 순으로 복잡하고 느립니다.
Collisions은 빈번하지 않아야 하며, 약간의 지연만 발생시켜야 하는데, 감수할 수 있는 정도는 괜찮습니다. 그렇기에 일반적으로 가끔 발생하는 collisions을 완전히 피하는 해시 함수보다는 약간 collisions이 있으면서 더욱 빠른 알고리즘이 선호됩니다.
Division-based 구현은 대부분 모든 칩 아키텍쳐에서 division은 microprogrammed 되기에 많은 고민이 되는 부분입니다. Modulo 연산은 변형되어 multiply by the word-size multiplicative-inverse of the constant로 처리될 수 있습니다. 하드웨어의 구조에 따라서 이러한 divide를 우회하는 개선이 많이 고민되었고 적용되었습니다.
Deterministic
해시 프로시져는 반드시 deterministic해야 합니다.
Reference
[1] https://en.wikipedia.org/wiki/Hash_function
[2] https://en.wikipedia.org/wiki/List_of_hash_functions
[3] https://en.wikipedia.org/wiki/Hash_table
[5] https://en.wikipedia.org/wiki/Birthday_problem
반응형'SE General' 카테고리의 다른 글
4년차 자바 백엔드 기술 질문들 (1) 2022.03.14 'THE RED: 김민태의 React와 Redux로 구현하는 아키텍쳐와 리스크관리' 후기 - 강의내용요약 (0) 2022.02.02 정수형 데이터 타입(Integer)의 해시 알고리즘 (0) 2021.10.27 내가 받았던 백엔드 인터뷰 질문들 (Java, Spring) (2) 2021.09.28 도커의 보안(Security) 알아보기 (0) 2021.08.16 도커(Docker)의 네트워킹 (1) 2021.08.02 HTTP의 역사 (2) 2021.08.02 모바일 네트워킹의 모빌리티(Mobility) (0) 2021.07.28