-
도커(Docker)의 네트워킹SE General 2021. 8. 2. 22:12반응형
도커는 애플리케이션을 컨테이너 안에서 실행하고, 실행되는 애플리케이션은 여러 네트워크를 통해 통신을 해야합니다. 이 사실은 도커가 강한 네트워크 역량이 필요하다는 점을 알려줍니다. 그 부분을 위해서 도커는 컨테이너-to-컨테이너, 기존에 존재하던 네트워크와 VLAN으로의 연결을 지원합니다. 후자는 VM이나 물리 서버 같은 외부에 존재하는 서비스와 연동하는 컨테이너화된 앱에서 더욱 중요합니다.
구성을 간략하게 살펴보면, 도커 네트워킹은 Container Network Model (CNM)이라고 불리는 오픈소스 pluggable 아키텍쳐에 기반해 있습니다. libnetwork는 도커의 실제 CNM 구현체로 도커의 핵심 네트워킹 기능을 제공합니다. 드라이버는 libnetwork에 플러그인되어 특정한 네트워크 토폴로지를 제공합니다.
또한, 편의를 위해서 도커는 대부분의 네트워킹 요구사항을 만족시키는 native 드라이버를 포함하고 있습니다. 이러한 것들에는 single-host 브릿지 네트워크, multi-host 오버레이와 기존의 VLAN에 연결되는 옵션 등이 존재합니다. 또한, 특정 드라이버를 제공하기 위해서 이러한 것들을 확장할 수 있습니다.
그리고 libnetwork는 native 서비스 디스커버리와 기본적인 컨테이너 로드밸런싱을 제공합니다.
이 글에서는 도커 네트워킹과 관련해 [1]의 요약을 중심으로, 아래와 같은 사항들을 더욱 깊게 살펴보겠습니다:
- 배경이론
- Single-host bridge 네트워크
- Multi-host overlay 네트워크
- 기존의 네트워크에 연결하기
- 트러블슈팅을 위한 컨테이너 및 서비스 로그
- 서비스 discovery
- Ingress 네트워킹
배경이론
하이레벨에서 볼 때, 도커 네트워킹은 3가지 컴포넌트로 구성됩니다:
- Container Network Model (CNM) - Design [3]
CNM은 디자인 명세입니다. 그렇기에 CNM은 도커 네트워크의 기반을 이루는 빌딩 블록들에 대한 개요를 전달합니다. 도커에 의해 제안된 스탠다드이나, 아래의 libnetwork 뿐만 아니라 Calico, Cisco Contiv, Open Virtual Networking(OVM), VMware, Weave, Kuryr 등 다양한 프로젝트와의 연동도 제공합니다.
- libnetwork - Primitives (Control & Management plane)
libnetwork는 CNM의 실제 구현체로 도커가 사용합니다. Go로 작성되었으며, CNM이 그려놓은 것들 중에 핵심적인 컴포넌트들을 구현하고 있습니다.
- 드라이버 - Networks (Data plane)
드라이버는 VXLAN 오버레이 네트워크와 같은 특정한 네트워크 토폴로지를 구현하며 모델을 확장합니다.
그럼 3가지 각각을 좀 더 살펴보겠습니다.
Container Network Model (CNM)
모든 것은 디자인으로 시작하고, 도커 네트워킹의 디자인이 바로 CNM입니다. 디자인에 관한 CNM의 전문은 [2]에 기술되어 있습니다.
CNM의 주요 빌딩 블록은 샌드박스, 엔드포인트, 네트워크 3가지로 구성됩니다.

CNM - Image from Author inspired by [1] 샌드박스는 고립된 네트워크 스택입니다. 샌드박스는 이더넷 인터페이스, 포트, 라우팅 테이블, DNS 설정을 포함합니다.
엔드포인트는 가상 네트워크 인터페이스입니다 (즉, veth - virtual ethernet device). 일반적인 네트워크 인터페이스처럼, 엔드포인트는 연결을 만드는 부분을 담당합니다. CNM의 케이스에서는 샌드박스를 네트워크에 연결하는 것이 이 엔드포인트의 역할입니다.
네트워크는 하나의 스위치(802.1d bridge)를 소프트웨어로 구현한 구현체입니다. 스위치와 같이, 네트워크는 통신할 엔드포인트들을 묶거나, 분리하는데 사용할 수 있습니다.
도커 환경에서 스케쥴링의 atomic 단위는 컨테이너로, 이름에서 알 수 있듯이 CNM은 이 컨테이너에 네트워크를 제공하는 방법에 관해 다루고 있습니다.

CNM's main components - Image from [2] 위에서 가장 왼쪽의 컨테이너는 하나의 인터페이스 (엔드포인트)가 백엔드 네트워크에 연결되어 있고, 중간의 컨테이너는 2개의 인터페이스가 각각 백엔드, 프론트엔드 네트워크에 연결되어 있습니다. 2개의 컨테이너는 서로 통신이 가능한데, 그 이유는 동일한 백엔드 네트워크에 둘 다 연결되어 있기 때문입니다. 그러나 중간에 존재하는 컨테이너의 2개의 엔드포인트는 layer 3 라우터에 도움 없이는 서로 통신할 수 없습니다.
엔드포인트는 일반적인 네트워크 어댑터와 동일하게 오직 하나의 네트워크에만 연결될 수 있습니다 (일반적인 어댑터 [4]와 유사). 그러므로, 컨테이너가 여러 개의 네트워크에 연결되기 위해서는 여러 개의 엔드포인트가 필요하게 됩니다.
아래 이미지에서와 같이 Docker Host는 고려하면, 컨테이너 A와 B 모두 동일한 호스트에서 실행됩니다. 하지만, 컨테이너 각각의 네트워크 스택은 샌드박스를 통해 OS-레벨로 완전하게 분리되어 존재합니다.

Host and CNM - Image from Author inspired by [1] Libnetwork
CNM이 디자인 문서라면, libnetwork는 그대로 구현한 구현체입니다. libnetwork [5]는 오픈소스로 Go로 작성되었으며 cross-platform(리눅스, 윈도우)하며 도커가 사용하고 있습니다.
도커 초창기에는 모든 네트워킹 관련 코드가 데몬에 존재하였습니다. 유닉스의 모듈 원칙을 따르지 않고 과도한 코드가 몰려 있었는데요. 이후 CNM의 원칙을 따라서 libnetwork로 떨어져나와 리팩토링 되었습니다. 현재 모든 도커의 네트워킹 코드는 libnetwork에 존재합니다.
CNM에서 정의된 3가지 컴포넌트를 모두 포함하고 있으며 native service discovery, ingress-based 컨테이너 로드밸런싱과 네트워크 컨트롤 및 관리 plane 기능을 구현하고 있습니다.
드라이버
libnetwork가 컨트롤 및 관리 plane 기능을 구현했다면, 드라이버는 데이터 plane을 구현합니다. 예로, 연결과 isolation은 모두 드라이버에 의해 처리됩니다.
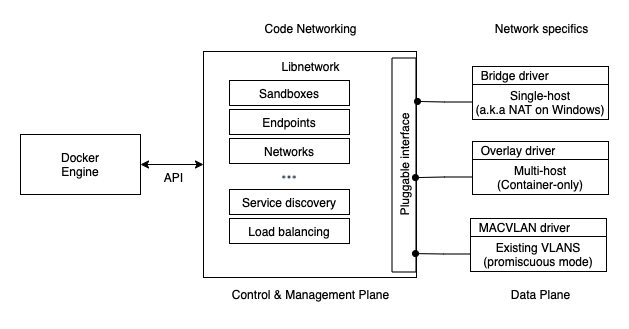
Overview - Image from Author inspired by [1] 도커는 몇 가지 빌트인 드라이버를 가집니다 (native 드라이버). 리눅스 상에서 도커는 bridge, overlay, macvlan 드라이버를 가지며, 윈도우 상에서는 nat, overlay, transparent, l2bridge를 가지고 있습니다.
제3자 역시도 remote 드라이버 (또는 플러그인)을 작성하여 도커 네트워크 드라이버로 사용할 수 있습니다. Weave Net이 바로 그러한 형태이며, 도커허브에서 다운로드 받을 수 있습니다.
각 드라이버는 담당하는 네트워크 상의 모든 리소스를 생성하고 관리하는 역할을 합니다. 예로, overlay 네트워크는 overlay 드라이버가 소유하고 관리하게 됩니다. 그렇기에 overlay 네트워크 상의 모든 리소스를 생성하고, 관리하고, 삭제할 때 overlay 드라이버를 호출하게 됩니다.
복잡한 환경에 대한 요구사항을 만족하기 위해서 libenetwork는 동시에 여러 네트워크 드라이버를 사용할 수 있도록 합니다. 그렇기에 도커는 성질이 다른 여러 네트워크를 지원할 수 있습니다.
Single-host bridge 네트워크
도커 네트워크의 가장 간단한 형태는 바로 단일 호스트 브릿지 네트워크입니다:
- 단일 호스트: 오직 하나의 도커 호스트에만 존재하며 같은 호스트에 존재하는 컨테이너들을 연결
- 브릿지: 802.1d 브릿지 (레이어 2 스위치)의 구현체
리눅스 상에서 도커는 빌트인 브릿지 드라이버로 단일 호스트 브릿지를 생성합니다. 반면, 윈도우 상에서는 빌트인 nat 드라이버를 사용합니다. (포트매핑이 추가되면 VM에서의 브릿지 네트워크와 유사하게 동작 - 참조 [6])
아래 이미지와 같이 2개의 도커 호스트가 동일한 로컬 브릿지 네트워크를 가지고 있다고 하더라도, 각각 독립된 네트워크이기에 서로 통신이 불가능합니다:
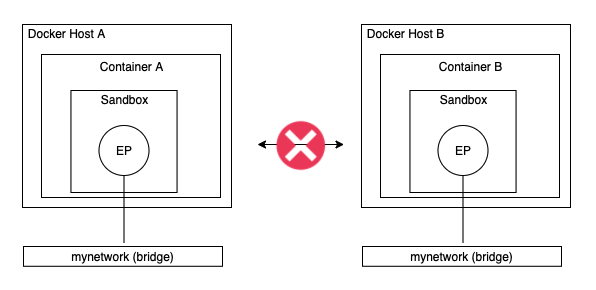
No communication between containers in different hosts - Image from Author inspired by [1] 모든 도커 호스트는 한 개의 디폴트 단일 호스트 브릿지 네트워크를 가집니다. 리눅스 상에서는 "브릿지"라고 불리고, 윈도우 상에서는 "nat"라고 불리는데요. 디폴트로 이 네트워크는 --network 옵션을 통해 입력하지 않는한 새롭게 생성되는 모든 컨테이너에 연결됩니다.
네트워크는 아래와 같은 커맨드를 통해 리스트할 수 있습니다:
// linux $ docker network ls NETWORK ID NAME DRIVER SCOPE 323f1231d421 bridge bridge local // window $ docker network ls NETWORK ID NAME DRIVER SCOPE 192nsdkf9123 nat nat local네트워크에 대한 좀 더 상세한 정보를 얻기 위해서는 아래와 같은 inspect 커맨드를 사용할 수 있습니다:
$ docker network inspect bridge [ { "Name": "bridge", "Id": "..." ...도커 네트워크는 리눅스 호스트의 bridge 드라이버를 통해 만들어졌는데, 이 bridge 드라이버는 리눅스 커널에 20년이 넘게 존재하던 것입니다. 그렇기에 매우 고성능에 안정적인 특성을 가집니다. 또한, 스탠다드 리눅스 도구를 사용하여 그러한 드라이버들을 살펴볼 수 있습니다:
$ ip link show docker0 3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc... link/ether 02:42:af:f9:eb:4f brd ff:ff:ff:ff:ff:ff모든 리눅스 기반의 도커 호스트에서의 디폴트 "브릿지"는 아랫 단의 커널의 리눅스 브릿지를 "docker0"로 매핑합니다. 아래와 같은 커맨드를 통해서 더욱 확실하게 확인할 수 있습니다:
$ docker network inspect bridge | grep bridge.name "com.docker.network.bridge.name": "docker0",도커의 디폴트 네트워크인 "bridge"와 리눅스 커널의 "docker0" 브릿지의 관계는 아래와 같습니다. 리눅스의 브릿지 "docker0"는 포트 매핑을 통해 이더넷 인터페이스에 연결됩니다.
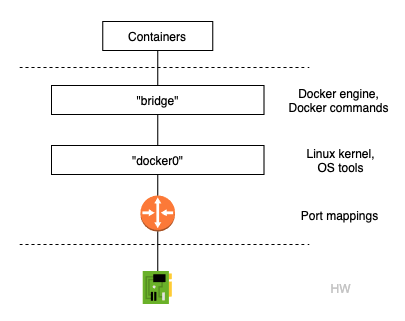
Image from Author inspired by [1] 그러한 도커 네트워크는 아래와 같이 생성할 수 있습니다:
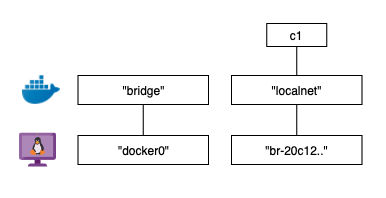
// linux $ docker network create -d bridge localnet // windows $ docker network create -d nat localnet이어서 리눅스의 brctl 도구를 사용하여 현재 시스템 상의 리눅스 브릿지를 확인할 수 있습니다:
$ brctl show bridge name bridge id STP enabled interfaces docker0 8000.12123nio no br-20c12312m1 8000.ret9nieo no위에서 2개의 브릿지를 보여주고 있는데, "docker0"는 앞에서 살펴본 것이고 두번째인 "br-20c12312m1"은 새롭게 생성한 "localnet"에 연결된 브릿지입니다. 2개 모두 spanning tree가 enabled 되어있지 않고, 기기(interfaces)에 연결되어 있지 않습니다.
Spanning Tree Protocol (STP) is a Layer 2 protocol that runs on bridges and switches. The specification for STP is IEEE 802.1D. The main purpose of STP is to ensure that you do not create loops when you have redundant paths in your network. Loops are deadly to a network. [7]
이후 아래와 같이 하나의 컨테이너를 생성하며 "localnet"에 연결해 볼 수 있습니다:
$ docker container run -d --name c1 --network localnet alpine sleep 1d이후 "localnet"을 inspect해보면 새롭게 생성된 "c1" 컨테이너가 잘 연결되어 있는 것을 알 수 있습니다:
$ docker network inspect localnet --format '{{json .Containers}}' ... "Name": "c1", ...다시 리눅스의 brctl으르 실행해보면 interfaces 컬럼에 이름이 존재하는 것을 알 수 있습니다:
$ brctl show bridge name bridge id STP enabled interfaces br-20c12312m1 8000.ret9nieo no vethe1231d docker0 8000.12123nio no그렇기에 현재 연결 상태는 아래와 같습니다:
Connection status - Image from Author inspired by [1] 위에서 아래와 같이 "localnet"에 연결된 새로운 컨테이너 "c2"를 생성하면, "c2" 컨테이너에서 "c1" 컨테이너로 DNS를 통해 접근할 수 있습니다 (디폴트 네트워크는 불가):
$ docker container run -it --name c1 --network localnet alpine sh // in c2 $ ping c1 ... $ ipconfig위에서는 bridge 네트워크가 연결된 컨테이너가 같은 네트워크에 있는 컨테이너에서만 접근이 가능하였습니다. 하지만 포트매핑을 통해서 다른 네트워크에 존재한는 컨테이너에서, 호스트의 로컬에서 접근할 수 있습니다.
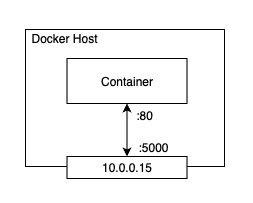
Port mapping - Image from Author inspired by [1] 위 이미지에서 컨테이너 안에서 실행되는 애플리케이션은 포트 80에서 실행되고 있습니다. 이것은 호스트의 10.0.0.15 인터페이스의 5000 포트에 매핑되어 있습니다. 그렇기에 10.0.0.15:5000를 통해 컨테이너 안의 애플리케이션에 도달할 수 있습니다.
Multi-host overlay 네트워크
오버레이 네트워크는 멀티 호스트입니다. 하나의 네트워크가 여러 호스트를 포함할 수 있기에 다른 호스트에 존재하는 여러 컨테이너들이 서로 통신할 수 있도록 해줍니다. 도커는 오버레이 네트워크를 위한 native 드라이버를 제공합니다. 그렇기에 간단하게 docker network create 시 --d overlay 옵션을 넣어 생성할 수 있습니다.
또한, 도커는 윈도우 상에서도 거의 리눅스와 동일한 오버레이 네트워크를 제공해주는데요. 오버레이 네트워크는 많은 클라우드-네이티브 마이크로서비스 앱의 중심에 있으며, 많은 애플리케이션 환경이 다른 호스트 및 다른 네트워크 간의 통신에서도 안정성 있고 안전한 네트워크를 요구하기에 오버레이 네트워크는 매우 중요합니다.
2015년 Docker 회사는 컨테이너 네트워킹 스타트업인 Socket Plane을 인수하였습니다. 이 인수의 2가지 목적은 도커에 '진짜 네트워킹'을 더하고 컨테이너 네트워킹을 단순화하여 심지어 개발자가 처리할 수 있도록 하는 것이었습니다. 그렇기에 하이레벨의 실행에서는 간단하지만, 내부에는 많은 복잡한 구성을 가지고 있습니다.
스웜 모드에서 도커 오버레이 네트워크 만들기
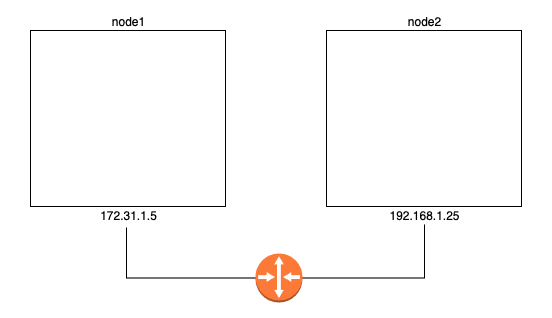
Image from Author inspired by [1] 아래에서 위의 이미지와 같이, 2개의 분리된 레이어 2 네트워크가 하나의 라우터에 연결된 상항을 가정하고 진행하도록 하겠습니다.
스웜 생성
가장 처음에 할 일은 2 호스트를 하나의 스웜으로 설정하는 것입니다. 스웜 모드는 오버레이 네트워크를 사용하기 위해서 필요한데요 (standalone의 경우 오버레이 네트워크 생성 시 --attachable 옵션을 넣어주어야 붙일 수 있음). 아래와 같이 node1에서 docker swarm init으로 간단하게 생성해줍니다:
$ docker swarm init \ --advertise-addr=172.31.1.5 \ --listen-addr=172.31.1.5:2377다음에는 node2를 설정해주어야 하는데요. 그전에 아래와 같은 포트에 대한 방화벽이 잘 열려있는지 확인해야 합니다:
- 2377/tcp: 매니지먼트 plane용
- 7946/tcp, 7946/udp: control plane용
- 4789/udp: VXLAN 데이터 plane용
$ docker swarm join \ --token SWMTKN-1ohz2ec...2vye \ 172.31.1.5:2377 This node joined a swarm as a worker.이렇게 2개의 노드(node1은 manager, node2는 worker)로 구성된 스웜을 만들었습니다.
새로운 오버레이 네트워크 생성
이제 node1에서 아래와 같은 커맨드를 통해 새로운 오버레이 네트워크를 생성할 수 있습니다:
$ docker network create -d overlay uber-net lsjirlanio42klnidsfnasd12위와 같이 스웜의 모든 호스트에서 가용한 새로운 오버레이 네트워크를 만들었으며, 네트워크의 control plane은 TLS로 암호화됩니다. data plane을 암호화하기 위해서는 -o encrypted 옵션으로 가능하나, 성능상 부하를 줄 수 있어 테스트 후 적용하는 것이 바람직합니다.
여기서의 control plane은 클러스터 관리 트래픽을 말하고, data plane은 애플리케이션 트래픽을 말합니다.
네트워크를 살펴보면 아래와 같습니다:
$ docker network ls NETWORK ID NAME DRIVER SCOPE ddac4ff813b7 bridge bridge local 389a7e7e8607 docker_gwbridge bridge local a09f7e6b2ac6 host host local ehw16ycy980s ingress overlay swarm 2b26c11d3469 none null local c740ydi1lm89 uber-net overlay swarm새롭게 생성한 오버레이 네트워크를 가장 마지막에 있는 것으로, 다른 네트워크들은 스웜 생성 시 자동으로 생성됩니다.
node2에서 docker network ls를 실행하면 uber-net을 볼 수 없는데, 그 이유는 컨테이너가 작업을 실행할 때만 새로운 오버레이 네트워크가 worker 노드로 확장되기 때문입니다. 이러한 lazy 방식은 확장성에 기여합니다.
오버레이 네트워크에 서비스 붙이기
이제 새로운 서비스를 생성해 네트워크에 붙여보겠습니다:
$ docker service create --name test \ --network uber-net \ --replicas 2 \ ubuntu sleep infinity위 커맨드를 통해 새로운 서비스 test를 생성해 uber-net에 붙이고 2개의 레플리카를 생성할 수 있습니다 (docker service ps로 확인).
오버레이 네트워크 테스트
이후 각 노드에서 다른 노드를 ping하여 테스트 해볼 수 있습니다.
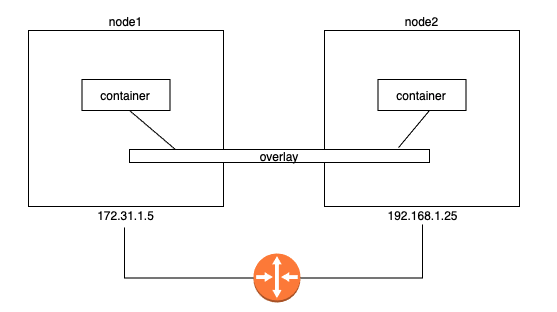
Image from Author inspired by [1] 내부 DNS를 통해 컨테이너 이름을 통해 서로 접근이 가능하나, 상세한 부분을 살펴보기 위해 컨테이너의 ip를 통해 접근해보도록 하겠습니다.
먼저, 아래와 같은 커맨드를 통해 대상 오버레이 네트워크에 연결된 컨테이너들을 살펴볼 수 있습니다:
$ docker network inspect uber-net ... "Subnet": "10.0.0.0/24", ... "Containers": { ... "IPv4Address": "10.0.0.3/24", ... "IPv4Address": "10.0.0.4/24", ...다른 많은 정보가 출력되나, 먼저 오버레이 네트워크의 서브넷이 10.0.0.0/24 인것을 알 수 있습니다. 또한, 연결된 컨테이너들의 각 ip도 확인할 수 있습니다. 그러한 각 컨테이너의 ip는 각 컨테이너 안에서도 아래와 같은 커맨드를 통해 확인할 수 있습니다:
$ docker container ls CONTAINER ID ... 396c8b142a85 ... $ docker container inspect \ --format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' 396c8b142a85 10.0.0.3결국 아래와 같이 레이어 2 오버레이 네트워크가 2개의 호스트를 연결하고 있고, 각 컨테어너는 각각 ip를 가지고 있어 ip로 서로 접근하는 것이 가능한 부분을 알 수 있습니다.

Image from Author inspired by [1] $ docker exec -it 396c8b142a85 bash // in the container $ ping 10.0.0.4 PING 10.0.0.4 (10.0.0.4) libc-bin (2.31-0ubuntu9) ... ... $ traceroute 10.0.0.4 ... ... test-svc.2.97v...a5.uber-net ...어떻게 동작하는지 자세히 알아보기
VXLAN
가장 먼저 도커 오버레이 네트워크를 VXLAN 터널을 사용하여 레이어 2 오버레이 네트워크를 생성합니다. 하이레벨에서 VXLAN은 가상 레이어 2 네트워크를 기존에 존재하던 레이어 3 인프라 위에 만들 수 있게 해줍니다. 이것의 의미는 엄청나게 복잡한 내부 요소들을 감추는 간단한 네트워크를 생성할 수 있다는 점인데요. 위에서는 10.0.0.0/24 레이어 2 네트워크를 2개의 레이어 2 네트워크(172.31.1.0/24, 192.168.1.0/24)로 구성된 레이어 3 ip 네트워크에 기반해 생성하였습니다.
VXLAN의 뛰어난 점은 encapsulation 기술로 기능하며 기존에 존재하던 라우터와 네트워크 인프라를 일반적인 IP/UDP 패킷으로 인식하고 별다른 이슈 없이 처리한다는 부분입니다.
가상 레이어 2 오버레이 네트워크를 만들기 위해서, 하나의 VXLAN 터널은 기존의 레이어 3 IP 인프라를 통해 생성됩니다. 가끔 이 레이어 3 IP 네트워크를 underlay 네트워크라고 부르기도 합니다.
VXLAN 터널의 각 끝에는 VXLAN Tunnel Endpoint (VTEP)가 존재하게 됩니다. VTEP는 encapsulation/de-encapsulation과 이러한 통신이 잘 이뤄지도록 여러 기능을 수행합니다.
앞에서 살펴본 예시에서도 오버레이 네트워크 생성을 위해 VXLAN 오버레이 네트워크를 사용합니다.
그것을 위해서, 각 호스트에서 새로운 sandbox(네트워크 네임스페이스)가 생성됩니다. Sandbox는 컨테이너와 유사하나, 애플리케이션을 실행하는 대신 독립된 네트워크 stack을 실행합니다 (호스트의 네트워크 stack으로부터 sandboxed-분리되어 있음).
Br0라고 불리는 하나의 가상 스위치(가상 브릿지)가 샌드박스 안에서 생성됩니다. 또한 Br0 가상 스위치와 연결된 VTEP도 생성되며, 다른 한쪽 끝은 호스트의 네트워크 stack(호스트의 VTEP)에 연결됩니다. 호스트 네트워크 stack의 끝부분은 호스트가 연결된 underlay 네트워크 상에서의 ip를 얻고 UDP 소켓의 포트 4789에 바운드됩니다. 이후 아래와 같이 각 호스트의 VTEP는 VXLAN 터널을 통해 오버레이 네트워크를 생성합니다.
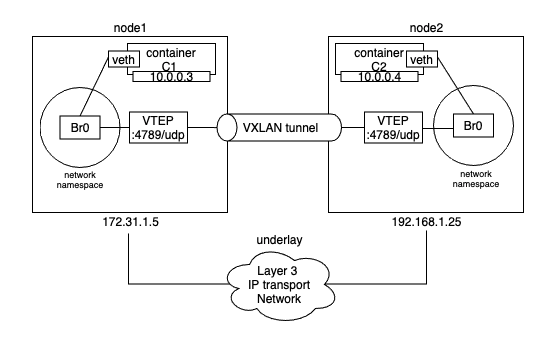
Image from Author inspired by [1] 통신 진행 방식을 살펴보면, C1은 ping 요청을 목적지 ip 10.0.0.4에 대해 수행합니다. 트래픽은 해당 컨테이너의 veth 인터페이스에 보내지고, veth는 Br0 가상 스위치에 연결되어 있습니다. 그 가상 스위치는 목적지 ip 주소에 해당되는 MAC 주소가 MAC 주소 테이블(ARP table)에 없어서 패킷을 어디로 보낼지 모릅니다. 그렇기에 연결된 모든 포트에 패킷을 보냅니다. Br0에 연결된 VTEP 인터페이스는 그 프레임을 어떻게 포워딩해야 하는지 알고 있기에 자신의 MAC 주소로 응답합니다. 이 부분은 proxy ARP reply이며 Br0 스위치가 어떻게 패킷을 포워딩해야하는지 학습하게 됩니다. 그 결과, Br0는 ARP 테이블을 업데이트하고 10.0.0.4를 로컬 VTEP의 MAC 주소로 매핑합니다.
(관련해 아래 글 참조)
웹페이지 요청 후 응답을 받기까지... (feat. DHCP, UDP, IP, Ethernet, DNS, ARP, BGP, TCP, HTTP)
| 이 글은 많은 부분 [1]을 차용하였습니다 네트워크는 5 layers, OSI 7 계층 등과 같이 여러 가지 레이어로 나누어 구분되곤 합니다. 하지만 단순한 하나의 웹페이지 요청 후 응답을 받는데도 여러
kadensungbincho.tistory.com
이제 Br0 스위치는 C2로 어떻게 패킷을 포워딩해야 하는지 알기에, 이후 C2로 보내지는 패킷은 직접 VTEP 인터페이스로 보내집니다. VTEP 인터페이스는 C2에 대해 알고 있는데, 새롭게 시작되는 컨테이너 모두 자신의 네트워크 정보를 스웜 상의 다른 모든 컨테이너에 빌트인 gossip 프로토콜을 통해 전파하기 때문입니다.
패킷은 VTEP 인터페이스로 보내져 underlay transport 인프라를 통해 보내질 수 있도록 프레임을 캡슐화합니다. 하이레벨로 보면, 이러한 캡슐화는 각 이더넷 프레임에 VXLAN 헤더를 추가하는 등의 작업이 포함됩니다. VXLAN 헤더는 VLAN으로부터의 프레임들을 VXLAN으로(또는 반대) 매핑하는데 사용되는 VXLAN network ID (VNID) 등을 가지고 있습니다. 각 VLAN은 VNID에 매핑되어 수신측에서 패킷을 de-encapsulation하고 정확한 VLAN에 포워딩 될 수 있도록 합니다. 이러한 부분을 통해 네트워크 독립성을 유지합니다.
이 캡슐화는 destination IP 필드에 해당되는 node2의 remote VTEP의 IP주소와 UDP 포트 4789 소켓 정보를 가진 UDP 패킷 안에 프레임도 래핑합니다. 이러한 캡슐화는 underlay 네트워크가 VXLAN에 대해 어떠한 것도 알지 못하여도 underlay를 통해 데이터가 송신될 수 있도록 해줍니다.
패킷이 node2에 도달하면, 커널은 그 패킷이 UDP 포트 4789로 전달되는 것을 알아봅니다. 그 커널은 해당 소켓에 바운드된 VTEP 인터페이스가 있다는 것을 알기에, 패킷을 VTEP로 보내고, VTEP에서 VNID를 읽고, 패킷을 de-encapsulate하고 VNID에 해당되는 VLAN 상의 로컬 Br0 스위치로 보냅니다. 이후 컨테이너 C2로 보내집니다.
또한, 도커는 같은 오버레이 네트워크 상에서 레이어 3 라우팅을 지원하는데요. 예로, 2개의 서브넷을 가진 오버레이 네트워크를 생성할 수 있습니다 (docker network create --subnet=10.1.1.0/24 --subnet=11.1.1.0.24 -d overlay prod-net). 그러면 2개의 가상 스위치가 생성되어 연결되게 됩니다.
기존의 네트워크에 연결하기
컨테이너화된 애플리케이션이 외부 시스템이나 물리적인 네트워크에 연결되는 부분은 매우 중요합니다. 예로, 애플리케이션이 일부만 컨테이너화된 경우에는 반드시 필요한 요구사항입니다.
빌트인 MACVLAN 드라이버는 이러한 요구사항을 위해 만들어 졌습니다. 이 드라이버를 통해 각 컨테이너가 각각의 MAC 주소를 가질 수 있도록 합니다.
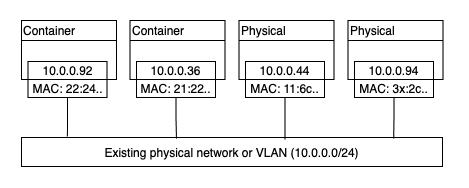
ip and mac - Image from Author inspired by [1] 위 구조의 장점은 MACVLAN은 포트 매핑이나 추가적인 브릿지가 필요없어 성능이 뛰어나다는 점입니다. 하지만 단점은 호스트 NIC가 promiscuous mode [8]여야 하며, 보통이 모드는 상용 네트워크나 퍼블릭 클라우드 플랫폼에서 허용되지 않습니다. 그렇기에 MACVLAN은 기업 데이터 센터에는 적절하나, 퍼블릭 클라우드에서 사용할 수는 없습니다.
VLAN을 2개 가진 물리 네트워크가 존재하고, 하나의 도커 호스트가 연결되어 있다고 하면 아래와 같은 구조를 가집니다:
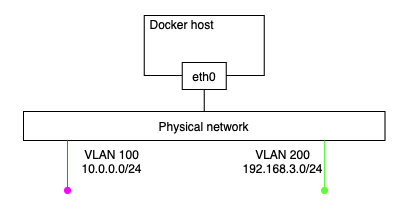
Image from Author inspired by [1] 이후 VLAN 100에 연결된 컨테이너를 생성하는 것이 요구사항이라고 할 때, 먼저 macvlan 드라이버를 사용하는 네트워크를 먼저 생성해야 합니다. 그리고 그러한 macvlan 드라이버를 사용하는 네트워크를 생성하기 위해서는 subnet info, gateway, 컨테이너에 할당되는 ip range, 호스트가 어떤 인터페이스 또는 서브 인터페이스를 사용할지 명시해야 합니다:
$ docker network create -d macvlan \ --subnet=10.0.0.0/24 \ --ip-range=10.0.0.0/25 \ --gateway=10.0.0.1 \ -o parent=eth0.100 \ macvlan100이후의 아래와 같은 커맨드를 통해 컨테이너를 생성하면, 해당 컨테이너는 VLAN 100에 존재하는 다른 시스템과 통신할 수 있게 됩니다:
$ docker container run -d --name macc1 --network macvlan100 alpine sleep 1d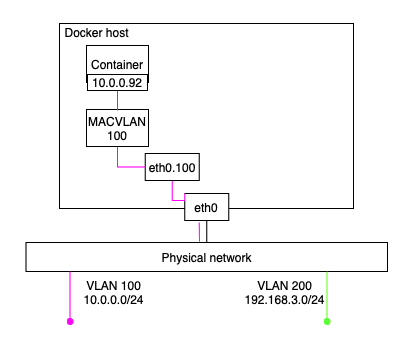
Image from Author inspired by [1] 트러블슈팅을 위한 컨테이너 및 서비스 로그
네트워크 연결과 관련한 문제를 해결할 때에는, 도커 데몬 로그나 컨테이너 로그를 확인하면 빠르게 디버깅할 수 있습니다.
윈도우 상에서 데몬 로그는 ~/AppData/Local/Docker 아래에 생성됩니다. 리눅스 상에서는 사용하는 init 시스템에 따라 다릅니다. 만약 systemd를 사용하면 로그는 journald로 가게되고 journlctl -u docker.service 커맨드를 통해 확인할 수 있습니다. 그 위치는 리눅스 종류에 따라 다릅니다:
- upstart 실행 Ubuntu: /var/log/upstart/docker.log
- RHEL 기반: /var/log/messages
- Debian: /var/log/daemon.log
또한, 도커의 설정(daemon config file)을 변경하여 로깅 레벨을 변경할 수 있습니다 (debug, info, warn, error, fatal).
Standalone 컨테이너는 docker container logs로, swarm 서비스 로그는 docker service logs를 통해 확인할 수 있는데 도커는 여러 로깅 드라이버를 지원하기에 모두 docker logs로 접근할 수 있지는 않습니다.
데몬 로그를 위한 드라이버와 설정 뿐만 아니라, 도커 호스트는 컨테이너를 위한 디폴트 로깅 드라이버와 설정을 가집니다. 드라이버들은 아래와 같습니다:
- json-file (default)
- journald
- syslog
- splunk
- gelf
위 컨테이너 로깅 설정은 daemon.json을 바꾸거나 (디폴트), 컨테이너 생성 시에 옵션(--log-driver, --log-opts)을 사용해(개별) 변경할 수 있습니다.
컨테이너 로그는 애플리케이션이 컨테이너의 PID 1 프로세스이고 STDOUT, STDERR를 내뱉을 때 동작합니다.
서비스 discovery
모든 핵심 네트워킹과 유사하게, libnetwork 또한 중요한 네트워크 서비스를 제공합니다. 서비스 디스커버리는 모든 컨테이너들과 Swarm 서비스가 서로를 이름을 통해 찾을 수 있도록 합니다. 그를 위해 필요한 요구사항은 그것들이 같은 네트워크에 존재하기만 하면 됩니다.
아래 이미지는 컨테이너가 도커의 임베디드 DNS 서버와 DNS resolver를 사용하는 형태를 보여줍니다:

Image from Author inspired by [1] 또한, 위와 같이 도커의 embedded DNS를 사용하는 것이 아니라, --dns 옵션 또는 각 컨테이너의 /etc/resolv.conf 파일을 통해 외부의 DNS를 바라보도록 할 수 있습니다:
$ docker container run -it --name c1 \ --dns=8.8.8.8 \ --dns-search=nigelpoulton.com \ alpine shIngress 로드밸런싱
Swarm은 서비스가 클러스터 외부에서 접근 가능하도록 2가지 형태의 퍼블리싱 모드를 제공합니다:
- Ingress 모드 (디폴트)
- Host 모드
ingress 모드로 퍼블리시되는 서비스는 Swarm의 어떤 노드에서든지 접근할 수 있습니다 (서비스 replicas 미실행 노드도). host 모드로 퍼블리시된 서비스는 서비스 replacas를 실행하고 있는 노드에서만 접근 가능합니다.
ingress 모드는 디폴트이기에, host 모드를 생성하기 위해서는 아래와 같이 옵션을 설정해주어야합니다:
$ docker service create -d --name svc1 \ --publish published=5000,target=80,mode=host \ nginx보통은 ingress 모드를 많이 사용합니다.
실제 동작방식은 ingress 모드는 서비스 메쉬(Service Mesh) 또는 스웜 모드 서비스 메쉬라고 불리는 레이어 4 라우팅을 사용합니다:
$ docker service create -d --name svc1 --network overnet \ --publish published=5000,target=80 nginx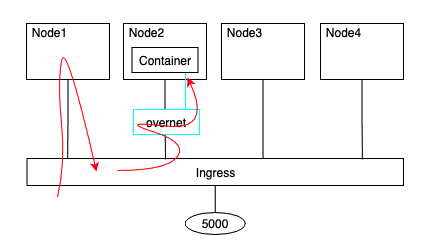
Image from Author inspired by [1] Reference
[1] Docker Deep Dive: Zero to Docker in a single book
[2] https://github.com/moby/libnetwork/blob/master/docs/design.md
[3] https://www.tigera.io/learn/guides/kubernetes-networking/container-networking/
[4] https://en.wikipedia.org/wiki/Host_adapter
[5] https://github.com/moby/libnetwork
[7] https://www.cisco.com/c/en/us/support/docs/lan-switching/spanning-tree-protocol/5234-5.html
[8] https://en.wikipedia.org/wiki/Promiscuous_mode
반응형'SE General' 카테고리의 다른 글
정수형 데이터 타입(Integer)의 해시 알고리즘 (0) 2021.10.27 내가 받았던 백엔드 인터뷰 질문들 (Java, Spring) (2) 2021.09.28 해시 알고리즘 특징 (0) 2021.09.27 도커의 보안(Security) 알아보기 (0) 2021.08.16 HTTP의 역사 (2) 2021.08.02 모바일 네트워킹의 모빌리티(Mobility) (0) 2021.07.28 리눅스(Linux) 단일 호스트 부하 디버깅 (feat. 서버/인프라를 지탱하는 기술) (0) 2021.05.26 셀레니움 내부구조 (Selenium Internals) (1) 2021.03.29