-
HDFS 네임노드 및 데이터노드의 기능과 구현Data 2021. 1. 20. 18:23반응형
HDFS는 하둡 환경에서 분산 파일 시스템 기능을 담당하는 하둡의 주요 모듈입니다. 이번 글에서는 HDFS와 관련해 다음과 같은 부분들을 다루고자 합니다:
- HDFS의 주요 목적
- HDFS 주요 개념 및 아키텍쳐
- HDFS(하둡분산파일시스템) 읽기, 쓰기, 삭제 시의 Flow 살펴보기
- HDFS 네임노드 및 데이터노드의 기능과 구현 (이번글)
관련글:
이 글에서는 네임노드와 데이터노드 각각 기능과 그 동작방식을 상세히 살펴보겠습니다.
네임노드의 기능과 구현
Namespace Management
네임노드는 네임스페이스를 관리합니다. 이러한 부분에는 3개의 데이터 구조과 연관되어 있습니다 [7]:
- Namespace: 각 노드의 메타데이터와 같이 네임스페이스는 파일 또는 디렉토리의 이름, permission 그리고 access time을 가지며 각 노드가 inode로 나타내지는 트리구조를 가지고 있습니다.
- BlockMap: 특정 파일을 구성하는 블록들에 대한 블록위치는 어떤 데이터노드에 위치하는지와 스토리지 정보를 가집니다. 블록 위치 정보는 블록맵 구조에 저장되어 있다가 클라이언트의 요청을 받을 때마다 해당 되는 블록을 찾아 반환합니다.
- InodeMap: 인덱스 구조의 InodeMap은 path에 해당되는 inode를 빠르게 찾아 반환합니다.
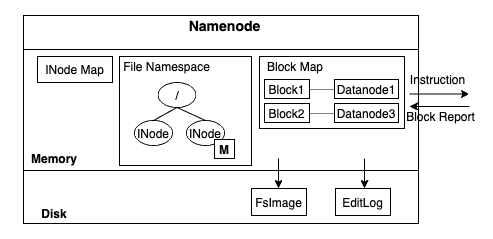
Namenode memory and disk - Image from Author inspired by [7] 블록 위치는 데이터노드로부터 주기적으로 송신되는 block report를 통해 유지됩니다. 그러나, 네임스페이스 재구성이 필요한 경우(주로 재시작)에는 모든 정보를 데이터노드에서 받을 수 없기에, 네임노드는 네임스페이스와 데이터노드에 보냈던 instruction과 같은 경우는 디스크의 로그형태로 기록하여 필요 시 replay할 수 있도록 합니다.
이러한 로그는 2가지 형태로 존재합니다: FsImage와 EditLog. FsImage는 inode의 숫자 FsImage 생성 시간, 실제 inode정보(inode permission, 파일을 이루는 block 정보 등) 등을 저장합니다. EditLog는 FsImage가 생성된 이후의 실행 operation들을 기록합니다.
이 두가지 로그 파일들은 사용하여 HDFS가 재시작할 때, 네임스페이스를 재구성할 수 있습니다. HDFS 네임노드의 성능은 로그 데이터를 디스크에 빠르게 flush할 수 있느냐의 여부에 따라 좌우됩니다. 아래 이미지와 같이 로그 파일을 쓰는데서 발생하는 지연은 희소한 자원인 RPC handler 쓰레드를 점유하고 있어서 전체 하둡 클러스터에 파급적인 영향을 미칠 수 있습니다:
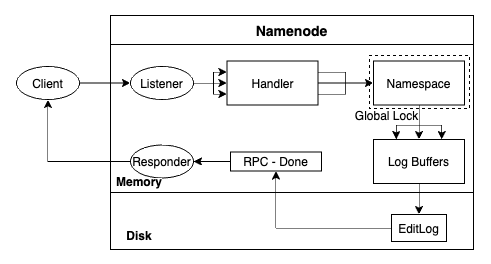
Namenode procedure to process client requests - Image from Author inspired by [7] Replica Placement
네임노드는 어떠한 방식으로 어떤 데이터노드에 블록을 저장할지 결정할까요? 이러한 결정에서 reliability와 write bandwidth, 그리고 read bandwidth 간의 trade off가 존재합니다.
예로, 블록의 모든 복제본을 하나의 노드에 쓰는 것은 가장 적은 write bandwidth 페널티를 가집니다만 전혀 실제 여분의 역할을 하지 못합니다(만약 해당 노드가 실패하면 블록의 모든 복제본이 접근 불가능합니다). 또한, off-rack read(해당 rack 외부의 읽기) 시에는 read bandwidth 페널티가 높습니다. 반대의 경우에는 여러 복제본이 각각 다른 노드에 저장되나 쓰기 시에 느리고, 읽기 시에 가장 근접 블록 복제본에 접근할 수 있습니다.
하둡의 디폴트 전략은 복제본을 클라이언트와 같은 노드에 놓는 것입니다. 그리고 rack, node, 해당 파일의 다른 블록의 위치 등을 반영하여 클러스터 전체에 블록 복제본들을 분산합니다.
Checkpoint
FsImage에 기반해 HDFS가 시작하고 운영하면 할수록 EditLog는 점점 커져갑니다. 이 경우 실패 후 재시작 시, EditLog를 통해 네임스페이스를 재구성하는데 시간이 오래 걸리게 됩니다. 그렇기에 네임노드는 주기적으로 FsImage에 EditLog를 반영하여 업데이트된 FsImage를 생성합니다.
업데이트 작업은 무거우며 active한 네임노드에서 실행되면 CPU와 RAM과 같은 자원이 부족할 수 있습니다. 이러한 부분을 해결하기 위해 두번째(secondary) 네임노드를 사용하게 됩니다. 이 경우 첫번째(active, primary)와 두번째 네임노드 간의 EditLog 업데이트는 아래와 같이 진행됩니다 [3]:
- 두번째 네임노드가 첫번째 네임노드에게 edits 파일을 flush하고 이후의 요청은 edits.new에 쓰도록 요청합니다.
- 두번째 네임노드는 fsimage 및 edits 파일을 복사해옵니다.
- 두번째 네임노드는 fsimage를 로드하고 edits을 fsimage에 기반해 replay하여 새로운 fsimage를 디스크에 씁니다.
- 두번째 네임노드는 새로운 fsimage를 첫번째 네임노드에게 보내고, 첫번째는 그것을 사용하게 됩니다.
- 첫번째 네임노드는 edits.new 파일을 edits로 이름을 변경합니다.
이러한 작업은 (디폴트 1시간) 주기적으로 실행되거나 (디폴트 64MB) edits 파일 크기가 일정한 수준에 도달한 경우 실행됩니다.
Block의 Creation, Re-replication, Rebalancing, Stale Detect
네임노드는 위('Replica Placement')와 같이 파일 생성 시에 블록 복제본을 위치시키지만, 어떠한 이유로 블록이 설정된 Replication Factor보다 적은 복제본을 가진 경우에도 re-replication을 위해 블록 복제본을 생성하고 위치시킵니다.
또 다른 하나의 경우는 시간이 흐르면서 여러 데이터노드에서 블록들의 분산이 고르지 않고 skew가 발생할 수 있습니다. 이렇게 unbalanced한 클러스터는 맵리듀스와 같은 처리엔진의 locality에 영향을 주거나 특정 데이터노드에만 요청이 몰려서 부하가 커지고 병목이 발생하는 경우도 있습니다.
Hadoop의 balancer 프로그램은 하둡 데몬으로 각 파일의 replication factor나 다른 정책(rack awareness 등)을 유지하면서 과도하게 사용되고 있는 데이터노드로부터 사용률이 낮은 데이터노드로 블록을 이동시킵니다. 이러한 경우 네임노드 역시 블록의 위치를 변경해주게 됩니다.
Stale Detect
클라이언트가 데이터노드로부터 데이터를 읽으며 checksums을 데이터노드에 저장된 checksum과 비교하며 검증합니다. 각 데이터노드는 영속적인 checksum verification 로그를 보관하는데 그것은 블록이 마지막으로 변경된 시점을 기록합니다. 클라이언트가 블록 검증을 마치면 데이터노드에 알리고 데이터노드는 그것을 로그에 기록합니다. 이러한 통계를 보관하는 부분은 bad disks를 감지하는데 이점이 됩니다.
위의 검증 단계에서 실패하면 클라이언트는 네임노드에 오류가 발생한 블록 복제본과 데이터노드를 알립니다. 네임노드는 해당 블록 복제본을 corrupt로 마킹하고 추후의 다른 클라이언트의 요청을 해당 블록 복제본으로 유도하지 않습니다. 그리고 해당 블록의 다른 복제본을 다른 데이터노드에서 다시 복사하여 replication factor를 맞추고 corrupt한 블록 복제본을 삭제합니다.
데이터노드의 기능과 구현
데이터노드는 HDFS의 실제 work horse로 File I/O와 보유하고 있는 블록의 integrity 관리를 담당합니다.
File I/O의 구조
읽기, 쓰기, 삭제 시의 Data Flow와 관련해서는 이 글에서 중점적으로 다루었습니다. 이 부분에서는 File I/O와 관련해 로컬 파일시스템(리눅스)-데이터노드가 어떤 구조로 이루어져 있고, 사용 시에 각 구조가 어떻게 사용되는지 알아보려 합니다.

Linux File System - Image from Author inspired by [5] HDFS의 File I/O는 데이터노드들에 기반하고 각 데이터노드는 해당 노드가 위치한 서버의 Storage에 의존합니다. 모던 컴퓨팅의 스토리지는 2가지 개념을 가지고 있습니다: persistent layer와 캐싱입니다. 영속성은 물리적 디스크(HDD, SDD 등)에 의해 이뤄지고, 캐싱은 서버의 멀티레이어에 의해 이뤄집니다. 그렇기에 비교적 복잡하고 파악이 어려운 캐싱이 HDFS I/O 성능에 어떻게 영향을 주는지 알아둘 필요가 있습니다.
높은 aggregate throughput과 노드 당 충분한 스토리지 용량을 제공하기 위해 주로 노드 당 12 ~ 24개의 물리 디스크를 마운트하게 됩니다. Hadoop Storage System(기반해 Kudu 등 다른 분산파일시스템도 접근 가능)은 ext4, XFS와 같은 리눅스 파일시스템 구현체에 의존합니다. 그러한 파일시스템 구현체는 리눅스에서 만들어둔 system call interface(POSIX를 따름)를 통해 접근합니다.
리눅스의 모든 system call은 파일시스템 자체가 invoke되기 전에, virtual filesystem(VFS)이라고 불리는 레이어를 통해 추상화됩니다. 하둡 admin은 이러한 VFS를 다룰 일은 없지만 존재 자체를 인지하고 있는 부분은 중요합니다. 이 VFS가 여러 마운트된 디스크를 같은 root-level 디렉토리 트리로 만들어 주어 단일하고 자동화된 파일시스템-리눅스 캐시 접근을 가능하게 합니다.
하둡 스토리지 시스템 - 리눅스 간의 주요 시스템 콜은 다음과 같습니다: read, write, open, seek / fsync / fflush / mmap / mlock.
리눅스는 유저 스페이스 또는 리눅스 커널이 사용하지 않는 메모리를 파일시스템을 위한 RAM-based 캐시인 page cache로 사용합니다. 리눅스의 모든 메모리는 4 KB 배수인 pages로 관리되는데, 페이지 크기는 보통 디스크와 호스트 시스템의 가장 작은 transfer 단위인 하드 디스크 블록 사이즈와 line up합니다.
리눅스의 페이지 캐시 사이즈는 런타임 동안 지속적으로 변경됩니다. 현재 크기의 페이지 캐시보다 큰 파일을 요청할 시에 리눅스는 가장 적게 쓰이는 페이지들을 디스크 스토리지에 저장하고 더 자주 쓰이는 새로운 파일을 위한 공간을 마련합니다. 현재 캐시 사이즈는 /proc/meminfo를 통해 확인할 수 있습니다.
하둡 역시도 이러한 리눅스 페이지 캐시에 이점을 이용합니다. 그렇기에 리눅스의 페이징은 하둡의 성능에도 중요한 요소입니다.
모든 리눅스 버젼은 빈번히 사용되지 않는 메모리 데이터를 특정 물리 디스크 공간에 저장하는 swapping 기능을 가집니다. Impala 또는 HBase 사용 시 이러한 스와핑은 악영향을 끼치기에 주로 사용하지 않을 것을 권장합니다. 리눅스는 sysctl 명령어를 통해 완전히 스와핑을 끌 수 있으나, 일부 최신 버젼에서는 oom 에러가 발생할 수 있기에 swapiness를 최소값으로 맞추면 됩니다.
어떠한 경우에는 리눅스 page cache를 피하는 것이 선호될 때가 있는데, 이러한 경우 O_DIRECT 플래그를 통해 최소화할 수 있습니다. 전반적으로는 메모리에 항상 일정 부분이 페이지 캐시에 사용될 수 있도록 적절한 메모리 분배가 필요합니다.
Integrity (Block Scanner)
각 데이터노드는 데이터노드가 가진 블록 복제본들에 대해 주기적으로 스캔을 행하고 블록 데이터와 checksum이 매치하는지 검증하는 블록 스캐너를 실행합니다. 각 scan이 진행되는 동안 설정된 시간 안에 검증 절차를 끝낼 수 있도록 읽기 속도를 조절합니다. 만약 클라이언트가 전체 블록을 읽고 checksum 검증이 성공했다면 데이터노드에게 알리고, 데이터노드는 그것을 검증된 것으로 간주합니다.
각 블록의 검증 시간은 사람이 읽을 수 있는 로그형태로 기록됩니다. 데이터노드의 최상위 디렉토리에는 언제나 최대 2개의 파일이 존재하는데, 그것은 current와 prev 로그입니다. 새로운 검증 시간은 현재 파일에 계속 append 됩니다. 상응하여 각 데이터노드는 복제본의 검증 시간 순으로 된 스캔한 블록 리스트를 메모리에 가지고 있습니다.
읽는 클라이언트나 블록 스캐너가 corrupt 블록을 발견 시에는 그 사실을 네임노드에 알립니다. 네임노드는 해당 복제본을 corrupt로 마킹하지만 바로 복제본 삭제를 스케쥴링하지는 않습니다. 대신, 먼저 확실한 복제본을 replication factor를 맞추기 위해 복사를 시작하고 맞춰지면 corrupt한 복제본을 삭제합니다. 이 정책은 최대한 데이터를 길게 보관하기 위함인데, 그렇기에 블록의 모든 복제본이 corrupt되었더라도 클라이언트는 해당 블록을 읽을 수 있습니다.
Reference
[4] HDFS Scalability: The limits to growth
[5] Architecting Modern Data Platform
반응형'Data' 카테고리의 다른 글
Data-Driven UX란? (0) 2021.01.23 YARN 리소스매니저(Resource Manager) (0) 2021.01.23 YARN(하둡분산자원관리) 실행 구조 및 흐름 (0) 2021.01.23 YARN(하둡분산자원관리) 주요개념 및 아키텍쳐 (0) 2021.01.21 HDFS(하둡분산파일시스템) 읽기, 쓰기, 삭제 시의 Flow 살펴보기 (0) 2021.01.20 HDFS(하둡분산파일시스템) 주요 개념 및 아키텍쳐 (0) 2021.01.20 YARN이란? (하둡분산자원관리) (0) 2021.01.19 HDFS란? (하둡분산파일시스템) (0) 2021.01.16