-
YARN(하둡분산자원관리) 주요개념 및 아키텍쳐Data 2021. 1. 21. 22:19반응형
하둡(Hadoop) 프로젝트의 YARN(Yet Another Resource Negotiaor) 모듈은 분산 환경에서의 자원관리를 담당합니다.
이 글에서는 YARN과 관련해 다음과 같은 항목을 다룹니다:
- 목적과 탄생배경
- 주요개념과 아키텍쳐 (이번글)
- YARN(하둡분산자원관리) 실행 구조 및 흐름
- YARN 리소스매니저(Resource Manager)
- YARN 노드매니저(Node Manager)
- 운영과 관련한 사항들
관련글:
YARN은 초기 하둡의 맵리듀스에 구현되어 있던 JobTracker와 TaskTracker에 기반해 발전했습니다. 더 뛰어난 확장성, 클러스터 사용률 부분이외에도 하둡 환경의 발전 관점에서 보면 Tez, Spark와 같은 다른 처리 엔진을 하둡 환경에서 실행할 수 있게된 부분이 주요하였습니다. 이 글은 YARN의 주요개념들을 살펴보며 YARN의 아키텍쳐와 기존의 하둡 맵리듀스와는 어떻게 다른지도 다뤄보겠습니다.
YARN의 주요개념들
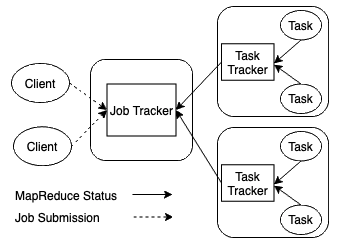
Hadoop(before YARN) 1.0 Architecture - Image from Author inspired by [2] YARN의 중심적인 개념을 구성하는 부분은 위 이미지의 JobTracker의 기능을 'job 스케쥴링 및 모니터링'과 '자원 관리' 부분 2가지로 나눈 부분입니다. 각각 global ResourceManager(RM)과 애플리케이션마다 생성되는 ApplicationManager가 바로 그 2가지를 구성합니다. RM은 노드마다 실행되는 NodeManager(NM)과 같이 분산 환경에서 애플리케이션을 관리하기 위한 새로운 고유한 운영체제 역할을 담당하게 되었습니다.
ResourceManager, Application Master, Node Manager
RM은 최상위의 구조체로 시스템 내의 다양한 애플리케이션에 자원을 분배하는 역할을 담당합니다. 그리고 애플리케이션 마다 생성되는 애플리케이션마스터(AM, 이 글에서 AM은 앱 마스터를 지칭)은 처리 엔진 프레임워크마다 다른 객체로(Spark는 스파크 전용, Tez는 Tez 전용 AM 생성) RM에 리소스를 요청하고 NM과 연동하여 task들을 실행하고 모니터링 합니다.
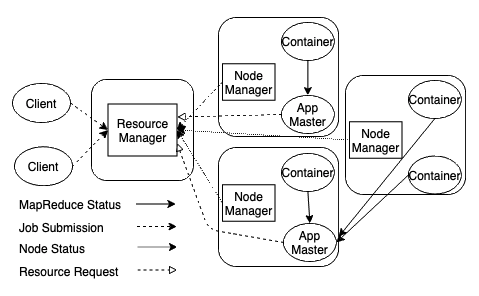
Hadoop 2.0 YARN Architecture - Image from Author inspired by [2] - 클러스터마다 생성되는 RM은 pluggable한 스케쥴러 컴포넌트를 가지고 있는데, 이것은 capacity, queue 등의 제약 속에서 다양한 애플리케이션에 자원을 분배하는 역할을 합니다. 이 스케쥴러는 모니터링과 애플리케이션 상태를 트래킹하는 부분에 전혀 관여하지 않는 다는 점에서 순수한 의미의 '스케쥴러'라고 할 수 있습니다 (작업 실패 시 재실행 같은 부분도 미관여). 스케쥴러는 메모리, CPU, disk, 네트워크 등의 요소로 구성되는 '리소스 컨테이너'라는 추상적인 개념을 통해 전달되는 애플리케이션의 '리소스 요구사항'에 기반해 스케쥴링을 실행합니다.
- 노드마다 생성되는 NM은 컨테이너를 실행하고 각 컨테이너의 리소스 사용량을 모니터링하고 그것을 RM에 report합니다.
- 애플리케이션마다 생성되는 AM은 스케쥴러와 연동되어 애플리케이션에 필요한 '리소스 컨테이너'를 조정하고, 각 컨테이너 상태를 트래킹하고 모니터링합니다. 구현 관점에서는 AM도 하나의 컨테이너로 normal 컨테이너에 속합니다.
Resource Model
YARN은 확장 가능한 자원 모델을 지원합니다(Hadoop 3.3). 디폴트로 YARN은 모든 노드, 애플리케이션, 큐의 CPU와 메모리를 추적합니다. 하지만, 자원에 대한 정의는 모든 임의의 countable한 자원을 포함하며 확장될 수 있습니다. Countable 자원은 컨테이너가 실행될 동안 소비하고 이후에 release되는 모든 자원을 말합니다. CPU와 메모리 모두 countable 자원이고, 다른 예시로는 GPU나 소프트웨어 라이센스 자원이 있습니다 [3].
추가로, YARN은 AWS EC2의 인스턴스 타입처럼(예로, large가 8 vCPU에 해당 되듯이), '자원 프로파일'을 지원합니다. 사용자는 사전에 정의된 자원 프로파일을 통해 다양한 자원 요청을 할 수 있습니다.
Resource Requests와 Containers
YARN은 각 애플리케이션이 클러스터의 자원을 공유하며 안전하고 multitenant 환경에서 사용할 수 있도록 설계되었습니다. 또한, 클러스터의 topology를 인식하여 데이터 이동을 최소화하는 스케쥴링을 하도록 고안되었습니다.
이러한 목적을 달성하기 위해, RM 안의 central 스케쥴러는 클러스터 안의 모든 애플리케이션을 고려해 더욱 적절한 스케쥴링을 할 수 있도록 애플리케이션에 관한 다량의 정보를 가지고 있습니다. 이 부분에서 중요한 개념인 ResourceRequest와 그 결과인 컨테이너가 등장합니다.
기본적으로 하나의 애플리케이션은 특정한 ResourceRequest들을 AM을 통해 보내고, 스케쥴러는 컨테이너를 할당하며 해당 요청에 응답합니다.
하나의 ResourceRequest는 아래와 같은 형태를 가집니다 [4]:
<resource-name, priority, resource-requirement, number-of-containers>- resource-name: hostname이나 rackname 중 하나로 자원 할당을 원하는 곳에 해당되며 선호가 없을 경우 *가 입력됩니다.
- priority: 한 애플리케이션 내부의 우선순위로, 주어진 애플리케이션 내에 존재하는 다양한 ResourceRequest 들의 순서를 정하게 됩니다.
- resource-requirement: 메모리 양이나 CPU 시간과 같은 필수적인 capabilities를 특정합니다.
- number-of-containers: 요청하는 컨테이너 갯수로 특정 ResourceRequest의 총 컨테이너 수를 제한합니다.
본질적으로 컨테이너는 RM이 하나의 특정 ResourceRequest를 허가한 성공결과로 자원 할당 자체입니다. 하나의 컨테이너는 특정 부분의 자원을 애플리케이션이 사용할 수 있도록 합니다.
AM은 반드시 컨테이너를 얻고 나서는 해당 컨테이너가 할당된 노드를 관리하는 NM에게 알리고 나서 자원을 사용하여 tasks를 실행할 수 있습니다.
Container Specification API
위에서 언급한대로 하나의 컨테이너는 단지 클러스터 내에서 하나의 노드에 특정 양의 자원을 사용하도록 허가한 것이기에, AM이 실제로 컨테이너를 launch하기 위해서는 NM에게 정보를 제공해야만 합니다. YARN은 하둡 맵리듀스와 달리 애플리케이션이 어떤 프로세스든(Java아닌 것도) 실행할 수 있도록 하고 있습니다.
YARN 컨테이너의 launch specification API는 플랫폼 중립적이며 아래와 같은 요소를 가집니다:
- 컨테이너 내에서 프로세스 생성을 위한 커맨드 라인
- 환경변수
- jars, shared object, 추가적인 데이터 파일과 같은 실행 전에 해당 서버에 존재해야하는 로컬 자원들
- 보안 관련 토큰들
이러한 디자인은 AM이 NM과 협력하여 간단한 쉡 스크립트부터 C / Java / Python 프로세스를 Unix / Windows / 가상환경 등에서 실행할 수 있게 만들어 주었습니다 (참고).
Timeline Server (예전의 JobHistory Server)
YARN의 현재와 과거 애플리케이션 정보를 저장하고 출력하는 부분은 timeline 서버를 통해서 처리됩니다. 타임라인 서버는 크게 2가지 목적을 가집니다 [5]:
- 애플리케이션 특정 정보 저장: 정보의 추출과 수집은 하나의 애플리케이션이나 특정 프레임워크에 따라 다릅니다. 예로, 맵리듀스는 맵 및 리듀스 task 숫자, 카운터 정보 등을 가지게 됩니다. 애플리케이션 개발자는 이러한 정보를 AM이나 컨테이너 안에 TimelineClient를 통해서 타임라인 서버로 publish 할 수 있습니다. 그리고 그러한 정보는 REST API나 애플리케이션/프레임웍 특정 UI를 통해 뿌려질 수 있습니다.

YARN Web UI - Image from Packt - 종료된 애플리케이션의 일반적인 정보 저장: 이전에 이 부분은 애플리케이션 히스토리 서버에 의해 맵리듀스 job만 지원되었습니다. 타임라인 서버를 추가하며 기능을 확장하였고 포함되는 일반적인 정보는 다음과 같습니다: 큐 이름, 유저 정보, 하나의 애플리케이션을 위해 실행된 애플리케이션-attempts 리스트, 각 애플리케이션-attempt와 관련한 정보, 각 애플리케이션-attempt에 의해 실행된 컨테이너 리스트, 각 컨테이너에 대한 정보 등.
(TODO)
Federation
Shared Cache
Reservation System
Reference
[1] Apache Hadoop YARN: yet another resource negotiator[2] Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2
반응형'Data' 카테고리의 다른 글
YARN 노드매니저(Node Manager) (0) 2021.01.27 Data-Driven UX란? (0) 2021.01.23 YARN 리소스매니저(Resource Manager) (0) 2021.01.23 YARN(하둡분산자원관리) 실행 구조 및 흐름 (0) 2021.01.23 HDFS 네임노드 및 데이터노드의 기능과 구현 (0) 2021.01.20 HDFS(하둡분산파일시스템) 읽기, 쓰기, 삭제 시의 Flow 살펴보기 (0) 2021.01.20 HDFS(하둡분산파일시스템) 주요 개념 및 아키텍쳐 (0) 2021.01.20 YARN이란? (하둡분산자원관리) (0) 2021.01.19