-
오라클 DB 아키텍쳐 살펴보기 (Database, Instance, Files, Memory, Process)SE General 2021. 3. 12. 06:53반응형
RDS란? - AWS의 관계형 데이터베이스 서비스들 알아보기
Amazon Web Service는 클라우드 환경에서 다양한 관계형 데이터베이스 서비스를 제공해주고 있습니다. 이 글에서는 관련된 중점 사항들은 무엇이 있고, 어떠한 서비스들이 존재하는지 알아보겠습니
kadensungbincho.tistory.com
오라클 데이터베이스(Oracle Database)는 오라클 기업에서 만든 멀티 모델 데이터베이스 시스템입니다. 그리고 오라클 DB는 주로 OLTP 또는 데이터 웨어하우징 작업에 사용됩니다.
1979년에 처음 출시되어 23번의 릴리즈(또는 버젼)을 만든 만큼 복잡하고 넓은 환경을 가지고 있습니다. 경쟁사의 Microsoft SQL Server, IBM의 Db2 등과 경쟁하고, 대안이 될 수 있는 다양한 오픈소스 MySQL, PostgreSQL 등도 존재합니다. 하지만, 굳건하게 시장점유율과 인기 순위에서 1위를 기록하고 있습니다 [1, 2].
MySQL을 주로 접하다가 이번 회사에서 Oracle DB를 접하고, MySQL과 비슷하면서도 간혹 익숙하지 않은 형태가 오라클 DB를 사용하다가 자주 발생하였습니다.
그렇기에 이번 글에서는 오라클 DB 아키텍쳐 오버뷰와 주요 컴포넌트를 살펴보려 합니다:
- 아키텍쳐 오버뷰
- 오라클 인스턴스와 데이터베이스에 대한 정의
- 오라클에 연결하기
- 파일
- 메모리
- 프로세스
아키텍쳐 오버뷰
오라클은 매우 portable(여러 곳에서 실행가능한)한 데이터베이스로 디자인 되었습니다. Windows, UNIX / Linux 등 다양한 환경에서 실행이 가능합니다. 하지만 오라클은 운영체제에 따라 다른 구조를 가지고 있습니다. 예로, UNIX/Linux 버젼에서는 오라클은 거의 기능 하나 당 한 개의 프로세스로 이루어지지만, Windows에서는 하나의 프로세스에 여러 쓰레드를 통해 그러한 부분이 구현되어 있습니다.
오라클 인스턴스와 데이터베이스에 대한 정의
오라클의 파일, 메모리, 프로세스 구조를 알아보기 전에 많은 혼동을 주는 용어인 오라클 데이터베이스와 인스턴스를 명확히 구분할 필요가 있습니다.
- 데이터베이스: 물리적인 운영 시스템 파일이나 디스크의 모음입니다. 오라클 오토스토리지관리 (Automatic Storage Management)나 RAW 파티션을 사용할 때, 데이터베이스는 각각의 분리된 파일로 운영 시스템에 존재하는 것이 아니나 정의는 동일하게 적용됩니다. 오라클 DB 12c에는 3가지 타입의 데이터베이스가 존재합니다.
- single-tenant 데이터베이스: self-contained 세트로 데이터 파일, 컨트롤 파일, redo 로그 파일, 파라미터 파일 등에 해당됩니다. 이러한 파일들은 오라클 메타데이터, 오라클 데이터, 오라클 코드, 애플리케이션 메타데이터, 애플리케이션 데이터 및 코드 등을 포함합니다. 12c 버젼 이전에는 유일한 데이터베이스 타입이었습니다.
- container 또는 루트 데이터베이스: self-contained 세트로 데이터 파일, 컨트롤 파일, redo 로그 파일, 파라미터 파일 등에 해당됩니다. 하지만 오직 오라클 메타데이터, 데이터, 코드만을 포함하며, 애플리케이션 관련 객체나 코드는 위의 파일들에 포함되어 있지 않습니다. self-contained이기에 다른 물리적 구조 지원 없이 마운트되고 open할 수 있습니다.
- pluggable 데이터베이스: 오직 데이터 파일 세트만을 가집니다. 또한, self-contained하지 않습니다. 이 데이터베이스는 plug되어 open되고 접근가능하기 위해서는 컨테이너 데이터베이스가 필요합니다. 가지고 있는 데이터 파일은 오직 애플리케이션 객체와 데이터 그리고 코드에 대한 메타데이터만을 포함합니다. 그렇기에 오라클 메타데이터나 오라클 코드는 포함되어 있지 않습니다.
- 인스턴스: 오라클 백그라운드 프로세스나 쓰레드 및 하나의 공유 메모리 영역의 모음입니다. 여기서 공유 메모리는 하나의 컴퓨터에서 실행되는 오라클 프로세스나 쓰레드가 공유하여 같이 사용하는 메모리 영역을 말합니다. 휘발성이 있어 persistant하지 않은 것들이 위치하는 곳으로 그 중 일부는 디스크로 flushed 됩니다. 그렇기에 인스턴스는 디스크 저장소 없이도 존재가 가능합니다.
위의 2가지 용어(데이터베이스와 인스턴스)는 가끔 혼동되어 사용되지만 매우 다른 개념을 다루는 다른 개념입니다. 2가지 개념의 관계는 (single-tenant 또는 컨테이너 데이터베이스의 경우) 데이터베이스가 마운트되고 여러 인스턴스가 그 데이터베이스에 접근하는 형태가 됩니다. 하나의 인스턴스는 하나의 데이터베이스만 마운트하고 open 합니다.
pluggable 데이터베이스의 경우 위와 동일하게 하나의 데이터베이스는 여러 인스턴스와 연결됩니다. 하지만 인스턴스는 여러 pluggable 데이터베이스에 동시에 접근할 수 있습니다.
SGA와 백그라운드 프로세스
오라클 인스턴스와 데이터베이스가 어떤 형태로 구성되는지 살펴보면 아래와 같습니다:
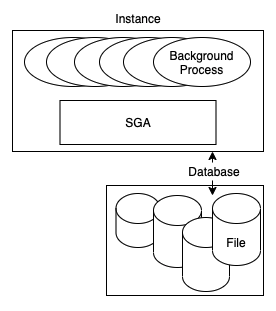
Oracle instance and database - Image from Author inspired by [3] 위 이미지에서 아래와 같은 기능들을 하는 메모리 부분인 SGA를 가집니다:
- 모든 프로세스가 접근하는 내부 데이터 구조를 유지
- 디스크로부터 얻은 데이터 캐싱, 디스크에 쓰기 전에 redo 데이터 버퍼
- parsed SQL 플랜 보관
- 기타
오라클은 이러한 SGA에 '부착된' 프로세스들을 가지며, 그렇게 부착되는 메커니즘은 운영체제마다 다릅니다. UNIX/Linux 환경에서 그 프로세스들은 큰 공유 메모리 부분에 물리적으로 부착되어 있습니다. 그러한 메모리는 OS에 의해 할당되며 다양한 프로세스가 concurrent하게 접근합니다.
윈도우 환경에서는 이러한 프로세스들은 단순히 C call인 malloc()을 사용하여 메모리를 할당하는데, 실제로 하나의 큰 프로세스 예하의 쓰레드들로 동일한 가상 메모리 환경을 공유하기 때문에 그렇습니다.
오라클은 또한 데이터베이스 프로세스들이나 쓰레드들이 read/write하는 데이터 파일을 가집니다. single-tenant 아키텍쳐에서 이러한 파일들은 테이블 데이터, 인덱스, 임시공간, redo 로그, PL/SQL 코드 등을 보관합니다. Multitenant 아키텍쳐에서 컨테이너 데이터베이스는 오라클 관련 메타데이터, 데이터, 코드를 보관하며, 애플리케이션 데이터는 pluggable 데이터베이스에 분리되어 보관됩니다.
UNIX/Linux 환경에서 오라클 DB를 실행하고, ps 커맨드를 통해 프로세스를 살펴보면 pmon, smon과 같은(추후 언급될) 다양한 프로세스가 실행되고 있는 것을 볼 수 있습니다. 이러한 프로세스들은 독립된 프로그램이 아니며, 모든 프로세스들은 단 하나의 오라클 binary executable을 다양한 방법으로 실행하여 생성됩니다.
오라클에 연결하기
이 부분에서는 오라클 서버에 연결하는 2가지 주요 방법을 살펴봅니다. 전용(dedicated) 서버와 공유(shared) 서버 연결이 바로 그것입니다. 그리고 2가지 방법에 따라 primary 네트워킹 프로토콜인 TCP/IP가 어떻게 커넥션을 이루는지 살펴보겠습니다.
전용 서버
전용 서버를 통해 오라클에 연결하게 되면 새로운 프로세스(또는 윈도우에서는 쓰레드 - 이하 동일)가 전용으로 생성되며 아래와 같은 형태의 연결을 이룹니다:

Dedicated Server Structure - Image from Author inspired by [1] 위에서 언급된 것과 같이, 각 세션마다 하나의 새로운 전용 서버가 생성되어 1:1 매핑을 이루게 됩니다. 전용 서버 프로세스는 인스턴스에 해당되지 않습니다(정의 상). 전용 서버 프로세스는 클라이언트와 통신하며 요청받은 SQL을 클라이언트를 대신해 실행하고 클라이언트를 대신해 응답을 받아 클라이언트에 전달합니다.
공유 서버
오라클은 공유 서버라는 형태로 연결을 받을 수 있는데, 이러한 경우에는 각 세션마다 새로운 프로세스를 생성하지 않습니다.
공유 서버 구조에서 오라클은 다수의 클라이언트를 위한 공유 프로세스 풀을 가지며 연결 풀링 메커니즘을 이룹니다. 이러한 형태는 오라클이 다수의 클라이언트에 연결될 수 있도록 만듭니다.
공유 서버와 전용 서버 커넥션의 가장 큰 차이는 데이터베이스에 연결된 클라이언트가 공유 서버에 직접 연결되지 않는다는 점(전용 서버와 달리)입니다. 프로세스가 공유되기 때문에 클라이언트는 직접 공유 서버에 연결될 수 없습니다. 클라이언트와 공유 서버를 연결해주기 위해서 오라클은 dispatcher라고 불리는 프로세스들은 운영합니다.
클라이언트는 네트워크를 통해 dispatcher에 연결되고, dispatcher 프로세스는 클라이언트의 요청을 SGA에 있는 요청 큐에 넣습니다. 공유 서버들 중 바쁘지 않은 처음의 프로세스가 이 요청을 맡게되고 처리하게 됩니다. 이러한 요청 처리 후, 공유 서버는 응답을 dispatcher 응답 큐에 넣습니다. 그리고 dispatcher가 응답을 꺼내어 클라이언트에 전달하게 됩니다.
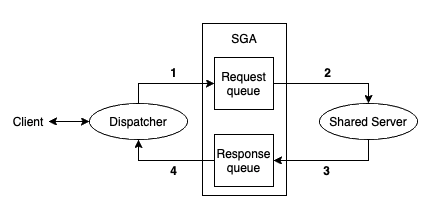
Shared Server Request & Response - Image from Author inspired by [1] TCP/IP 연결 구조
클라이언트가 다른 서버에 위치한 오라클에 TCP/IP 네트워크를 통해 연결한다고 할 때, 연결은 클라이언트로부터 시작됩니다. 클라이언트는 오라클 클라이언트 소프트웨어를 통해 하나의 요청을 생성합니다.
예로, sqlplus를 통한 연결은 아래와 같습니다:
sqlplus username@[//]host[:port][/service_name][:server][/instance_name]이제 클라이언트 소프트웨어는 어디로 연결해야될지 알기에, TCP/IP 소켓 연결을 위의 호스트네임을 가진 서버에 포트 1521로 생성합니다. 오라클 네트워크 환경에서, TNS 리스너라는 프로세스를 서버 상에 실행하게 됩니다. 이 리스너 프로세스가 데이터베이스에 물리적으로 연결되도록 해줍니다. 이 리스너가 inbound 연결 요청을 받으면, 요청을 조사하고 conf 파일을 사용하여 요청을 승인하거나 거부합니다.
전용 서버 연결을 만들게 된다면, 그 리스너 프로세스는 전용 서버 프로세스를 생성하게 됩니다. UNIX/Linux 환경에서 이것은 fork()와 exec() 시스템콜을 통해 진행됩니다. 새로운 전용 서버 프로세스는 리스너를 통해 만들어진 연결을 계승하게 되며, 물리적으로 데이터베이스에 연결되게 됩니다. 윈도우 환경에서 리스너 프로세스는 데이터베이스 프로세스에 쓰레드 생성을 요청하고 쓰레드가 생성되면 클라이언트는 쓰레드로 'redirect'됩니다.
그러나, 공유 서버 연결의 경우 리스너는 다르게 동작합니다. 리스너 프로세스는 인스턴스 안에서 실행되는 dispatcher(s)를 인지하고 있고 연결 요청을 받으면 풀 중의 하나의 dispatcher 프로세스를 선택합니다. 리스너는 이후 클라이언트에 어떻게 dispatcher 프로세스에 연결될 수 있는지에 대한 정보를 돌려주거나 dispathcer 프로세스로 클라이언트의 요청을 바로 넘깁니다(환경에 따라 다르나 결과는 유사).
리스너가 연결 정보를 클라이언트에 보내고나면 클라이언트가 dispatcher의 random port로 바로 연결될 수 있기에 리스너의 처리는 끝나게 됩니다.
Reference
[1] Wikipedia - Oracle Database
[3] Expert Oracle Database Architecture, Third Edition
[4] Practical Oracle SQL: Mastering the Full Power of Oracle Database
반응형'SE General' 카테고리의 다른 글
HTTP의 역사 (2) 2021.08.02 모바일 네트워킹의 모빌리티(Mobility) (0) 2021.07.28 리눅스(Linux) 단일 호스트 부하 디버깅 (feat. 서버/인프라를 지탱하는 기술) (0) 2021.05.26 셀레니움 내부구조 (Selenium Internals) (1) 2021.03.29 테크니컬 라이터란? (Technical Writer) (2) 2021.03.28 웹페이지 요청 후 응답을 받기까지... (feat. DHCP, UDP, IP, Ethernet, DNS, ARP, BGP, TCP, HTTP) (2) 2021.03.08 IPFS란? (InterPlanetary File System) (0) 2021.02.25 Brave 브라우저 (5) 2021.01.27 - 아키텍쳐 오버뷰