-
DDD란? ((Business) Domain-Driven (Software) Design)SE Concepts 2021. 3. 28. 14:02반응형
최근 외주로 운영 되던 서비스를 내재화하는 작업을 담당하게 되면서, 특정 도메인의 목적을 위해 구현된 소스코드를 이해하는 데에는 순전히 '기술적'인 사항만 존재하지 않는다는 사실을 절실히 깨달았습니다. '모바일 쿠폰 서비스'라는 컨택스트 상에서는 당연하고 상식적인 흐름이, 그러한 컨택스트를 제외한 '기술적'요소들만을 살펴보았을 때는 터무니 없이 복잡하고 어렵게 느껴졌습니다.
또한, 서비스에 요구사항을 전달하는 그 근본에는 '도메인'이 존재하기 때문에 서비스에 대한 이해는 '도메인에 대한 깊은 이해'에 기반한다는 점을 실감하고 있습니다.
많은 소프트웨어가 실패하고, 그러한 소프트웨어의 실패의 원인들은 대다수 '커뮤니케이션'과 관련된 문제점을 포함한다고 합니다 [2]. 이 부분에서 DDD(Domain-Driven Design)은 이러한 소프트웨어의 위기와 커뮤니케이션 문제를 해결하기 위한 시각을 제공하여 줍니다.
이 글에서는 아래와 같은 사항을 중점으로 DDD에 대해 다뤄보겠습니다:
- DDD란?
- Strategic Design
- 비지니스 도메인 분석
- 도메인 지식의 발견
- Bounded Context와 Context Mapping
- Tactical Design
- 비지니스 로직 구현 패턴
- 아키텍쳐 패턴
DDD란?
DDD는 요구사항을 모으는 것부터 low-level 디자인까지 소프트웨어 개발 라이프사이클 전체를 포함하는 방법론입니다. 가장 중심 전제에는, 더 나은 소프트웨어를 만들기 위해서 소프트웨어 디자인과 '비지니스 도메인, 요구 전략'을 일치시켜야한다는 점이 존재합니다. 그러한 사실에서 DDD라는 이름이 탄생하였습니다: (business) domain-driven (software) design.
이 글에서는 디자인적인 결정을 위한 두 가지 레벨의 관점을 통해 살펴봅니다: Strategic 및 Tactical level이 바로 그 2가지입니다:

Image from Author 먼저, Strategic 패턴과 실행은 기업의 비지니스 도메인을 분석하는 프레임웍을 제공하고 소프트웨어 문제 도메인을 만듭니다. 그리고 tactical 패턴은 소프트웨어 문제 도메인에 맞는 해결책을 구축할 수 있도록 low-level 디자인 결정을 지원하는 부분을 다룹니다.
Strategic Design
DDD의 원칙에 따르면, 효율적인 소프트웨어 디자인은 비지니스 도메인에 대한 지식과 문제 도메인을 모델링할 수 있는 능력을 요구합니다. 이 장에서는 도메인 지식의 발견과 모델링에 대해 다룹니다.
비지니스 도메인 분석
비지니스 도메인은 기업의 전반적인 활동 영역을 정의합니다. 일반적으로, 기업이 고객에게 제공하는 서비스에 해당됩니다(스타벅스 - 커피, 월마트 - 유통 등).
한 기업은 다수의 비지니스 모데인에 걸쳐 운영될 수 있습니다 (아마존 - 유통, 클라우드 컴퓨팅). 그리고, 기업의 도메인은 변경될 수도 있습니다 (Nokia - 목재 -> 고무 -> 통신).
비지니스 도메인은 그것을 구성하는 '서브도메인'들로 이루어지며, 도메인 및 서브도메인 지식은 '도메인전문가'로부터 탄생하게 됩니다.
서브도메인
위와 같은 비지니스 도메인의 목적을 이루기 위해서, 기업은 여러 서브도메인을 운영해야 합니다. '서브도메인'이란 전체 비지니스 활동의 세부적인 영역에 해당됩니다. 모든 서브도메인 영역들이 합쳐져 기업의 비지니스 도메인을 이룹니다.
기술적인 관점에서 보면 서브도메인은 내부적으로 연결된 사용례의 그룹과 유사합니다.
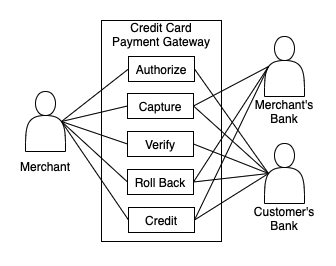
Image from Author inspired by [1] 위 다이어그램은 유사한 사용례 '세트'를 나타냅니다. 그러므로, 이러한 사용례들은 "신용카드결제"라는 서브도메인을 형성합니다.
서브도메인은 3가지 종류로 구성되어 있습니다: core, generic, supporting.
Core Generic Supporting 정의 경쟁자들과 기업이 '다르게' 행하는 서브도메인으로 새로운 제품이나 서비스를 개발하거나, 존재하던 프로세스를 최적화하는 것 등이 해당됩니다.
그리고 중요한 부분은, 코어 서브도메인이 반드시 기술적일 필요는 없다는 사실입니다. 모든 비지니스 문제가 알고리즘이나 기술적 해결책으로만 풀리지는 않습니다 (예로, 보석상이 온라인 사이트를 운영한다고 할 때 보석의 디자인 또는 브랜드가 코어 서브도메인이지 온라인 사이트의 엔진이 코어 서브도메인은 아니게 됩니다).제네릭 서브도메인은 코어 서브도메인만큼 복잡하고 구현이 어려우나, 기업에게 경쟁적 우위를 제공하지는 않는 서브도메인입니다. 그렇기에, 이 부분에 대한 혁신이나 최적화 요구가 존재하지 않습니다. 다른 표현으로는, 대다수의 기업들이 유사한 형태로 운영하고 있는 비지니스 활동이라고 할 수 있겠습니다. 이름에서 알 수 있듯이, 서포팅 서브도메인은 기업 비지니스는 지원하는 부분입니다. 그러나, 코어 서브도메인과 달리 서포팅 서브도메인은 기업에 어떠한 경쟁우위도 제공하지 않습니다. 복잡도 & 변경도 구현하기 쉬운 Core 서브도메인은 단기간의 경쟁우위만을 제공합니다. 그러므로, 코어 서브도메인은 본질적으로 복잡합니다. 기업의 코어 비지니스에는 높은 진입장벽이 있어서, 경쟁자가 복사하거나 모방하기 어려워야 하기 때문입니다.
또한, 코어 서브도메인은 자주 변경됩니다. 기업 비지니스 전략에는 코어 서브도메인은 지속적으로 혁신하고 진화시키는 것이 포함되기 때문입니다.- 코어와 서포팅 서브도메인의 가장 극명한 차이는 비지니스 로직의 복잡도입니다. 서포팅 서브도메인은 간단합니다.
또한, 서포팅 서브도메인은 기업에 어떤 경쟁우위도 제공하지 않기에 (변경에 대한 니즈가 없어) 자주 변경되지 않습니다.구현 코어 서브도메인은 인-하우스로 구현되어야 합니다. 다른 곳으로부터 구매하거나 아웃소싱할 수 없습니다.
기술적인 관점에서, 코어 서브도메인 비지니스 로직의 유지보수성과 진화는 매우 중요합니다. 그러므로, 코어 서브도메인은 가장 advanced한 엔지니어링 테크닉이나 높은 수준의 엔지니어를 요구합니다.제네릭 서브도메인의 구현은 어려우나 대부분 이미 해결된 부분들입니다. 오픈소스를 사용하거나, 구현된 제품을 구입하는 것이 보통 더욱 비용-효율적입니다. 경쟁우위가 부족하기에 인-하우스로 구현하는 것에 대한 필요성이 드무나, 제네릭 서브도메인과 달리 구현된 제품이 존재하지 않고 간단하기에 보통 단순한 형태로 구현하여 사용합니다.
높은 수준의 엔지니어는 코어 서브도메인을 위해 아껴두길 권장하며, 이 부분에 대한 아웃소싱도 고려해 볼 수 있겠습니다.도메인전문가
도메인전문가는 코드로 구현하고 모델링할 비지니스에 상세한 사항을 잘 알고 있는 전문가입니다. 다른 말로하면, 도메인전문가는 소프트웨어의 비지니스 도메인에서의 지식-권위자입니다.
도메인전문가는 요구사항을 수집하는 분석가도 아니고 시스템을 디자인하는 엔지니어도 아닙니다. 도메인전문가는 비지니스를 표현합니다. 비지니스의 문제를 가장 처음 식별하며, 모든 비지니스 지식은 도메인전문가로부터 탄생합니다.
일반적으로 도메인전문가는 요구사항을 발생시키는 사람이거나 소프트웨어의 엔드유저입니다. 그러한 소프트웨어는 그들의 문제를 해결할 수 있어야 합니다. 예로, 온라인 광고대행사에서의 도메인전문가는 캠페인매니저, 광고주, 분석가, 그리고 다른 비지니스 이해관계자가 될 수 있습니다.
도메인 지식의 발견
비지니스 도메인(또는 서브도메인)과 도메인전문가를 인지하였다면, 그로부터 도메인 지식을 배우거나 그러한 지식을 공유하는 방법을 알아볼 차례입니다.
이 섹션에서는 도메인 지식의 발견을 위해 가장 먼저 진행해야할 '문제정의를 위한 커뮤니케이션', 정의된 문제에 관해 커뮤니케이션하기 위한 'Ubiquitous Language', 그리고 특정 목적을 돕기 위해 충분히 추상적이고 충분히 구체적인 '모델'에 관해 기술합니다.
문제정의를 위한 커뮤니케이션
If I had an hour to solve a problem I’d spend 55 minutes thinking about the problem and 5 minutes thinking about solutions.
- Albert Einstein올바른 해결책을 만들기 위해서는 문제 도메인에 대한 지식이 필요합니다. 이러한 '문제 도메인에 대한 지식'은 앞에서 언급한 것처럼 도메인전문가에 속해 있습니다. Alberto Brandolini의 말처럼, 소프트웨어 개발은 배움의 과정이며 동작하는 코드는 부수적인 결과입니다. 소프트웨어 엔지니어는 어쩔 수 없이 비지니스 도메인에 대해 '빠삭하게' 이해하여야 합니다.
많은 소프트웨어 실패 사례에 대한 연구는 지식공유와 프로젝트 성공을 위해서는 효율적인 커뮤니케이션이 필수적임을 보여주고 있습니다. 그러나 그러한 중요성에도 소프트웨어 프로젝트에서 효율적인 커뮤니케이션은 찾아보기 힘듭니다.
보통, 비지니스 분석가, 프로덕트 오너, 프로젝트 매니저 등의 중간자를 통해 엔지니어에게 push down되는 지식과 프로세스는, (의도는 좋을지 몰라도) 정보가 손실되기에 지식공유에 해롭습니다.
Ubiquitous Language
유비쿼터스 언어는 DDD 실행의 초석이 됩니다. 그룹 간에 효율적인 커뮤니케이션이 필요하다면, 그룹들은 같은 언어를 사용하여야 합니다.
비록 이러한 개념은 상식에 해당되지만, 전통적인 소프트웨어 개발 라이프사이클을 살펴보면 여러 단계의 '번역'을 거치는 것을 알 수 있습니다:
1. 도메인지식이 분석모델로
2. 분석모델이 요구사항으로
3. 요구사항이 시스템디자인으로
4. 시스템디자인이 소스코드로
이렇게 연속적으로 도메인지식을 번역하는 대신, DDD는 비지니스 도메인을 나타내기 위해서 하나의 언어를 사용해야한다고 말합니다. 특히 도메인전문가는 비지니스 도메인을 나타내는데 유비쿼터스 언어를 사용하는데 익숙하여야 하고, 이 언어는 도메인전문가의 멘탈모델을 잘 반영하고 있어야 합니다.
이 부분에서의 주요 포인트는 일관성과 애매함의 배제, 그리고 동의어에 대해서는 컨택스트와 같이 전달하는 것입니다.
비지니스 도메인의 모델
모델은 실제 세상의 복사본이 아니며, 사람이 실제 세상을 더 잘 이해할 수 있도록 충분히 추상화되고, 충분히 구체적이게 만든 것입니다.
모델의 예로, 지도를 들 수 있습니다. 모든 지도는 지구의 모든 상세한 정보를 담고 있지는 않지만, 각 지도(지형지도, 네비게이션지도, 지하철지도 등)는 해결해야 하는 문제를 해결하기 위한 충분한 정보를 담고 있습니다.
위에서 유비쿼터스 언어를 개발하며, 비지니스 도메인의 모델을 효율적으로 구축해나가게 됩니다. 그러한 유비쿼터스 언어는 비지니스에 대한 모든 정보를 담을 필요는 없습니다. 필요한 시스템을 구현하는 것을 가능하게 하는 비지니스 도메인 측면에 대한 정보만 담을 수 있다면 충분합니다.
Bounded Context와 Context Mapping
한 기업이 영위하는 도메인 그리고 서브도메인의 범위는 매우 넓습니다. 그렇기에 하나의 용어도 세부적인 서브도메인에서는 다양한 의미로 사용되게 됩니다. 이러한 의미 차이는, 사람 간의 대면 커뮤니케이션에서는 해결할 수 있어도 소스코드에까지 그러한 불명확성이 담긴다면 문제가 발생하게 됩니다.
이러한 상황에서의 해결책은 유비쿼터스 언어에 명확한 컨텍스트(및 스코핑)를 적용하여 그러한 언어가 한정된 가정하에 사용되도록 하는 것입니다. 그러한 한정된 컨텍스트는 위에서 언급된 모델에도 적용되어야 합니다. 경기도 지도를 떠올린다면, 경기도 지도에서 '광주'는 명확하게 경기도 광주가 될 수 있습니다 (그러나 전국 이상의 지도에서는 경기도 광주인지, 전라남도 광주인지 헷갈릴 수 있습니다).
이런 Bounded 컨텍스트는 서브도메인과 각 범위에 따라 1:1, 1:N, N:1의 관계를 갖습니다. 그렇기에 기업 내의 도메인은 다양한 Bounded 컨텍스트로도 매핑될 수 있습니다.
컨텍스트끼리의 상호작용은 다양한 방식을 통해 이루어지며, 기업 내의 Bounded 컨텍스트를 파악하고 서로 간의 연동방식을 확인해두는 작업은 이후의 tactical 작업에 중요한 지도가 됩니다. 상호작용 방식은 다음과 같은 형태가 존재합니다:
- Partnership: Bounded 컨텍스트가 ad hoc하게 연동됩니다.
- Shared Kernel: 양쪽 모두에서 참조하는 하나의 컴파일된 라이브러리 형태로 연동 계약이 존재합니다.
- Conformist: 소비자가 서비스 제공자 모델을 따릅니다.
- Anticorruption layer: 소비자가 서비스 제공자의 모델을 소비자 자신의 요구에 맞는 형태로 변형하여 사용합니다.
- Open-host service: 서비스 제공자가 소비자 요구에 최적화된 언어를 구현합니다.
- Separate ways: 협업하고 연동하는 것보다 특정 기능을 하나 더 만드는 것이 비용이 더 적게 드는 형태입니다.
Tactical Design
비지니스 로직 구현 패턴
위에서 기업의 도메인은 다양한 서브도메인으로 구성되고 그러한 서브도메인은 여러가지 종류가 있다는 사실을 배웠습니다. 이 장에서는 그러한 서브도메인의 종류에 따라 어떠한 비즈니스 로직 구현 패턴이 적용될 수 있는지 살펴봅니다.
Transaction Script
이 패턴은 비즈니스 문제가 ETL 형태를 닮은 간단한 문제 도메인에 잘 적용될 수 있습니다. 각 오퍼레이션은 데이터를 원천으로부터 추출해 변형을 가하고 목적지에 저장하는 형태를 가집니다.
이 패턴의 구현은 간단합니다. 이러한 형태는 비즈니스 로직을 프로시져들로 구성하고, 각 프로시져는 시스템의 퍼블릭 인터페이스로부터의 요청을 구현합니다.
각 프로시져는 간단한 프로시져 스크립트로 구현됩니다. 저장소 처리 등과 같은 부분에 얇은 레이어가 추가될 수 있으나 직접 접근하는 형태여도 무방합니다.
프로시져에 대한 요구사항은 transactional한 형태라는 부분 외에는 존재하지 않습니다. 프로세스가 어떠한 형태로든 실패한다면, 시스템은 상태 변경 없이 그대로 잔존해야 합니다.
Active Record
위의 Transaction Script 패턴이 비즈닌스 로직이 간단한 곳에 적용되는 것과 같이 이 패턴도 간단한 곳에 적용되지만 비교적 좀 더 복잡한 데이터 구조를 가진 곳에 사용됩니다. 예로, 단순한 레코드 대신 트리 객체 형태나 수직적 구조를 가지고 있을 때 사용합니다.
이러한 데이터 구조를 가진 것에 단순한 transaction script 패턴을 적용한다면 매우 반복적인 코드를 작성하게 됩니다. 데이터를 메모리 상의 표현에 매핑하는 부분에서 지속적인 중복이 발생합니다.
결과적으로 이러한 패턴은 복잡한 데이터 구조를 나타내기 위해 특별하게 고안된 객체를 사용합니다. 데이터 구조를 제외하고도 이러한 객체들은 CRUD를 위한 데이터 접근 메소드를 구현하고 있습니다. 그렇기에 active record 객체는 ORM이나 다른 데이터 접근 프레임웍에 의존합니다. 이러한 패턴명은 각 데이터 구조가 active하는 점에 착안하여 따왔습니다.
역시 이러한 패턴도 비교적 간단한 비지니스 로직만 지원할 수 있습니다.
Domain Model
도메인 모델 패턴은 복잡한 비즈니스 로직을 처리를 목적으로 만들어졌습니다. 이 패턴에서는 CRUD 인터페이스 대신 복잡한 비즌니스 룰이나 protected 되어야할 불변값들을 다룹니다.
transaction script와 active record 패턴과 같이 도메인 모델은 마틴 파울러의 책 "Pattern of Enterprise Application Architecture"에서 소개되었습니다. 그러나, 이 패턴은 일 년 이후인 Eric Evans의 "Domain-Driven Design: Tackling Complexity in the Heart of Software"에서 자세하게 다루어 졌습니다.
구현
마틴파울러에 의해 정의된 도메인 모델은 행동과 데이터를 결합하는 도메인의 객체 모델입니다. Aggregates, value objects, domain events 등과 같은 DDD의 tactical 패턴은 그러한 객체 모델의 구성요소입니다.
복잡성
도메인 비지니스 로직은 이미 복잡하기에, 객체 모델링은 추가적인 복잡도를 더하지 않아야 합니다. 그러한 모델은 인프라스트럭쳐나 기술적 요소를 배제해야하기에 모델의 객체가 "plain old objects"(Java의 POJO)이도록 제한합니다.
유비쿼터스 언어
기술적인 요소 대신 비지니스 로직에 중점을 두는 것은 도메인 모델 객체가 bounded 컨텍스트의 유비쿼터스 언어를 반영하기 쉽게 만듭니다.
구성요소들
아래에서는 value objects와 aggregates를 살펴봅니다.
Value Objects
value object는 값에 의해 식별되는 객체입니다. 예로는,
class Color { int red; int green; int blue; }Color 객체의 한 필드의 변경은 다른 새로운 색을 나타내게 됩니다. 다른 두 가지 Color는 같은 값을 가지지 않습니다. 또한, 같은 Color의 두 인스턴스는 동일한 값을 가져야 합니다. 그러므로, color를 식별하기 위해 명시적인 식별 필드가 필요 없습니다.
필드의 변경은 다른 값을 나타내기에 value object는 immutable한 객체로 구현됩니다. 어떠한 액션이 새로운 값을 가져온다면, 기존 인스턴스를 변경하지 않고 새로운 인스턴스를 리턴해야 합니다:
class Color { Color mixWith(Color other) { // ... return new Color(...); } }Aggregate
Aggregate는 객체로 객체들의 수직구조를 나타냅니다. Value object와 대비되어, 그 객체는 오직 값을 통해서만으로는 식별할 수 없습니다. 이것은 각 aggregate는 식별되기 위해서 ID 필드가 필요하다는 뜻입니다.
예로, 같은 이름의 2명의 사람이 있다고 하면 이름이 같다고 똑같은 사람은 아닙니다. 그러므로, 사람을 식별하기 위해 특정 ID 필드가 필요합니다:
class Person { Guid id; String firstName; String lastName; }또한, value object와의 다른 점은 aggregate은 객체의 값으로만 식별할 수 없기 때문에 객체의 상태가 mutable하다는 점입니다.
- 일관성
Aggregate은 변형될 수 있기 때문에, 상태에 일관성을 보호하는 것이 매우 중요합니다. 일관성을 강제하기 위해서, aggregate 패턴은 aggregate과 외부 스코프의 경계를 명확하게 구분하여야 합니다. 오직 aggregate의 비지니스 로직만이 그것의 상태를 변경할 수 있습니다. Aggregate 외부의 모든 프로세스나 객체는 오직 상태를 읽거나 aggregate 객체의 퍼블릭 메소드만 실행할 수 있습니다.
그렇기에 aggregate 퍼블릭 메소드는 모든 비지니스 룰과 불변값을 강제하고 input을 검증하는 역할을 담당합니다. 이러한 엄격한 경계선은 또한 모든 aggregate 연관 비지니스 로직이 한 곳에서 관리될 수 있도록 합니다.
- 트랜잭션 경계
Aggregate의 상태는 자신의 비지니스 로직을 통해서만 변경될 수 있기에, aggregate 경계는 또한 트랜잭션 경계 역할도 합니다. Aggregate에 대한 모든 변경은 하나의 atomic 연산으로 트랜젹션을 통해 커밋되어야 합니다. 더욱이, 어떠한 시스템 수행도 multiaggregate 트랜잭션을 가정하지 않아야 합니다. Aggregate에 대한 변경은 각각 커밋되어야 합니다.
이 부분은 모델링에 제한을 가합니다. 그렇다면 같은 트랜잭션에서 여러 aggregate을 변경하고자 한다면 어떻게 해야 할까요?
- 객체의 수직구조
때때로 비지니스 시나리오에서 여러 객체가 같은 트랜잭션 경계를 공유해야 될 때가 있습니다.
DDD는 시스템 디자인이 비지니스 도메인을 통해 드리븐되어야 한다고 하고 있습니다. 그렇기에 aggregate도 비지니스 시나리오를 담을 수 있어야 합니다.
하나의 aggregate은 평평한 레코드가 아니라, 여러 연관된 객체가 수직구조를 이루는 하나의 문서입니다.
객체들의 수직구조는 만약 객체들이 도메인 비지니스 로직에 바운드된다면 같은 aggregate에 속할 수 있습니다. 이 부분에서 aggregate이라는 이름이 붙여졌습니다: 비지니스 요소들과 value object들을 하나의 같은 트랜잭션 경계로 aggregate하기 때문입니다.
- 다른 aggregate 참조하기
하나의 aggregate 안에 모든 객체들은 같은 트랜잭션 경계를 공유하기 때문에, 성능과 확장성 이슈가 발생합니다.
데이터의 일관성은 aggregate 경계를 디자인할 때 편리한 휴리스틱입니다. 오직 aggregate 비지니스 로직을 구현하는데 매우 강하게 일관될 필요가 있는 정보만 그러한 경계에 존재해야 합니다. eventually 일관될 수 있는 객체들은 aggregate에 속하면 안되며 그것들의 ID를 통해 참조될 수 있습니다.
가능한 aggregate을 작게 유지하고 비지니스 로직 상 반드시 일관성을 가져야 하는 객체들만을 포함하여야 합니다.
- Aggregate 루트
이전에 aggregate의 상태는 오직 포함하고 있는 메소드 중 하나를 실행해서 변경할 수 있다는 점을 살펴보았습니다. 하나의 aggregate은 객체들의 수직구조를 나타내기에 오직 그것들 중 하나만이 aggregate의 퍼블릭 인터페이스로 존재하여야 합니다.
Aggregate 루트에 더해서, aggregate이 외부와 커뮤니케이션하는 방법이 하나 더 존재합니다. 그것은 바로 도메인 이벤트입니다.
- 도메인 이벤트
도메인 이벤트는 비지니스 도메인에서 발생한 중요한 이벤트를 나타내는 메시지입니다. 예로, 주문결제, 주식매도 등이 될 수 있습니다.
도메인 이벤트는 이미 발생한 어떤 일을 나타내기에 그것들의 이름들은 과거형을 띄어야 합니다.
도메인 이벤트는 aggregate의 퍼블릭 인터페이스의 일부입니다. 하나의 aggregate은 그것의 도메인 이벤트를 발생시킵니다. 다른 프로세스와 aggregate, 심지어 외부 시스템은 이러한 이벤트를 subscribe하고 이러한 이벤트에 따라 각각의 로직을 실행할 수 있습니다.
Event-Sourced 도메인 모델
이벤트 소스 도메인 모델 패턴은 도메인 모델 패턴과 같은 가정에 기반합니다: 비지니스 로직은 복잡하고 핵심 서브도메인에 속합니다. 더욱이, 이벤트 소스 도메인 모델은 도메인 모델과 동일한 tactical 패턴을 사용합니다: value objects, entities, 그리고 aggregate과 aggregate 루트가 그것입니다. 이러한 두 가지 패턴의 구현 상의 차이는 aggregate의 상태가 영속화되는 방식에 존재합니다. 이벤트 소스 모데인 모델은 aggregate의 상태를 관리하기 위해 이벤트 소싱 기법을 사용합니다.
- 이벤트 소싱
CRM 시스템과 관련한 작업을 진행한다고 할 때, 아래와 같은 레코드를 가지고 있다고 가정하겠습니다.
Customer: b14061410 Name: Kaden Cho Phone: 010-8530-1231 Email: kadensungbincho@gmail.com State: Converted상태 기반의 시스템에서 위에서 보이는 값들은 그 고객에 대해 우리가 알고 있는 모든 것입니다. 그렇기에 이 고객이 어떻게 이러한 상태에 도달하게 되었는지는 알지 못합니다. 그가 상품을 직전에 구입했는지, 아니면 오랫만에 구입한 것인지 알지 못합니다.
이벤트 소싱 패턴은 도메인 이벤트를 사용하여 모델에 '시간'이라는 차원을 더합니다. 시스템 상태에 대한 모든 변경은 도메인 이벤트에 대한 기록으로 나타낼 수 있습니다.
이러한 도메인 이벤트는 고객 상태의 변경 이력을 보여줍니다:
1. 고객이 시스템에서 initialize됨
2. 세일즈 파트에서 고객에게 전화를 했었으나, 고객이 나중에 다시 전화를 다른 전화번호로 요청함
3. 그 고객이 다시 연결 시도 시 연락을 받고 상품을 구입함
위에서 살펴본 고객의 최종 상태는 이러한 시간에 따른 도메인 이벤트들이 최종적으로 만들어낸 상태입니다.
Source of Truth
이벤트 소싱 패턴이 동작하기 위해서는 객체 상태에 대한 모든 변경이 도메인 이벤트로 나타내어지고 영속되어야 합니다. 이러한 도메인 이벤트는 시스템의 source of truth가 됩니다.
시스템의 도메인 이벤트를 저장하는 데이터베이스는 단 하나의 일관된 저장소입니다(source of truth). 하나의 이벤트 소스 aggregate에 대한 수행은 아래와 같은 순서로 진행됩니다:
1. aggregate 도메인 이벤트 로드
2. 상태를 다시 생성함
3. 비지니스 로직은 실행하고 새로운 도메인 이벤트를 생성함
4. 새로운 도메인 이벤트를 데이터베이스에 커밋함
본질적으로 이벤트 소싱 패턴은 새로운 것이 아닙니다. 파이낸셜 산업은 ledger 내에서 변경을 나타내기 위해 이벤트를 사용합니다. Ledger는 append-only 로그로 트랜잭션을 기록합니다. 현재 상태는 ledger의 레코드를 프로젝션하여 언제든 재복원할 수 있습니다.
이점
일반적인 상태 기반의 표현에 비교해서 이벤트 소싱 모델은 aggregate을 모델링하기 위해 더 많은 노력을 요합니다. 그러나, 이러한 접근은 상당한 이점을 주기에 아래와 같은 상황에서 고려해 볼 수 있습니다:
Time machine
도메인 이벤트는 aggregate의 현재 상태 복원에 사용될 수 있기 때문에, aggregate의 과거의 모든 상태를 복원할 수도 있습니다.
Deep insight
이 글의 초반부에서 비지니스의 핵심 서브도메인을 최적화하는 것이 매우 중요하다는 사실을 살펴보았습니다. 이벤트 소싱은 시스템의 상태나 행동에 대한 깊은 인사이트를 제공합니다. 더욱이, 유연한 모델은 이벤트들을 기존에 계획하지 않았던 다른 상태로 변형하여 표현하는 것을 가능하게 합니다.
Audit log
영속화된 도메인 이벤트는 aggregate 상태에 일어난 모든 일들에 대한 일관된 audit log가 됩니다.
이러한 모델은 돈이나 통화 트랜잭션을 관리하는 시스템에 매우 편리합니다.
아키텍쳐 패턴
tactical 디자인 결정에 있어서 어떤 아키텍쳐 패턴을 사용할지 결정하는 부분은 매우 중요합니다. 적절한 패턴은 시스템의 기능 또는 비기능적 요구사항을 구현하도록 지원합니다.
이 장에서는 아키텍쳐 패턴과 사용례를 살펴봅니다: 레이어드 아키텍쳐, ports & adapters, CQRS 패턴.
레이어드 아키텍쳐
레이어드 아키텍쳐 패턴은 시스템 코드를 아래와 같은 세 가지 기술적 요소로 구조화합니다:
- 프레젠테이션 레이어: 유저 인터페이스를 present하고 정의함
- 비지니스 로직 레이어: 비지니스 로직을 구현함
- 데이터 액세스 레이어: 영속 메커니즘에 대한 접근을 제공함

Layered Architecture - Image from Author inspired by [1] 위의 레이어들은 한 방향으로 각각 참조하게 됩니다:
위 다이어그램에서 보듯이, 프레젠테이션 레이어는 비지니스 로직 레이어에 의존하고, 비지니스 로직 레이어는 데이터 액세스 레이어에 의존합니다.
사용례
비지니스 로직과 데이터 액세스 간의 의존성은 아키텍쳐 패턴을 active record 패턴을 사용하여 구현된 비지니스 로직에 적합하도록 만듭니다.
Ports & Adapters
포트 & 어댑터 아키텍쳐는 시스템의 코드베이스를 기술적인 요소에 기반해 분해한다는 점에서 레이어드 아키텍쳐와 유사합니다. 그러나, 그것은 아래와 같은 점에서 다릅니다:
- 용어: 포트 & 어댑터 아키텍쳐는 시스템 유저 인터페이스, 데이터 액세스 코드, 그리고 다른 모든 인프라스트럭쳐 부분을 표현하는 인프라스트럭쳐 레이어로 구성됩니다.
- 의존성: 기술적 요소들에 둘러쌓여 있는 대신에, 포트 & 어댑터 아키텍쳐에서는 비지니스 로직이 중심적인 역할을 합니다. 비지니스 로직은 시스템 인프라스트럭쳐 컴포넌트 어떤 것에도 직접적으로 의존하지 않습니다.
- 애플리케이션 레이어: 애플리케이션 레이어는 시스템 퍼블릭 인터페이스의 facade를 구현합니다. 시스템에 의해 노출되는 모든 오퍼레이션을 나타내고 그것들을 실행하기 위한 시스템 비지니스 로직을 관리합니다.

Port & Adapter - Image from Author inspired by [1] 인프라스트럭쳐 컴포넌트들의 연동
포트 & 어댑터 아키텍쳐의 중심 목표는 시스템 비지니스 로직을 인프라스트럭쳐 컴포넌트로부터 떨어뜨리는 것입니다.
인프라스트럭쳐는 직접적으로 참조하고 요청하는 대신에, 비지니스 로직 레이어는 인프라스트럭쳐 레이어에 의해 구현된 포트를 정의합니다. 그 인프라스트럭쳐 레이어는 어댑터를 구현하는데, 이 어댑터는 다르느 기술과 동작하기위한 포트의 인터페이스 역할을 합니다. 애플리케이션 레이어는 의존성 주입을 통해 비지니스 로직 포트를 위한 어댑터를 지원합니다.
예로, 아래에 메시지 버스를 위한 포트 정의와 구체적인 어댑터가 있습니다:
public interface IMessaging { void publish(Message payload); void subscribe(Message type, Action callback); } public class SQSBus : IMessaging { // ... }사용례
비지니스 로직은 모든 기술적 요소로부터 떨어뜨리는 것은 포트 & 어댑터 아키텍쳐를 도메인 모델 패턴으로 구현되니 비지니스 로직에 적합하도록 만듭니다.
CQRS: Command-Query Responsibility Segregation
CQRS는 여러 영속 모델에 데이터 표현을 가능하게 하는 아키텍쳐 패턴입니다.
Polyglot 모델링
여러 사례에서 모든 시스템 요구사항에 맞게 시스템 비지니스를 모델하는 것은 매우 어렵고 심지어 불가능한 일입니다. 예로, 다른 모델이 OLTP, OLAP 그리고 search를 구현하는데 적합합니다.
여러 모델과 동작하는 이유는 하나의 단일한 데이터베이스가 모든 시스템 요구사항을 지원하지 못할 때 적용되는 polyglow 영속화의 개념 때문이기도 합니다. 대신, 여러 데이터베이스를 사용하여 다양한 데이터 액세스 요구사항을 구현할 수 있습니다. 예로, 하나의 단일한 시스템은 operational 데이터베이스로 다큐먼트 스토어를 사용하고 분석/리포팅을 위해 컬럼형 스토리지를 사용하고, 검색 기능을 위해 검색 엔진을 사용할 수 있습니다.
아래에서 시스템 데이터의 다양한 모델은 나타내기 위해 CQRS가 어떻게 다양한 스토리지 메커니즘 사용을 가능하게 하는지 살펴보겠습니다.
구현
패턴의 이름에서 유추할 수 있듯이, 시스템 모델의 역할을 분리해야 합니다. 2가지 모델이 있는데 command execution 모델과 read 모델이 있습니다.
Command Execution 모델
CQRS는 하나의 모델을 시스템 상태를 변경하는 실행 수행을 위해 사용합니다 (OLTP). 또한, 이 모델은 source of truth가 되는 강한 일관성을 나타내는 유일한 모델입니다.
Read 모델 (Projections)
시스템은 다른 시스템이나 사용자에게 presenting하기 위해 여러 모델로 정의될 수 있습니다. 이러한 모델들은 read-only입니다.
- Read 모델을 프로젝팅하기
Read 모델이 동작하기 위해서는, 시스템은 command execution 모델의 변경을 모든 read 모델에 투영시켜야 합니다.

CQRS Architecture - Image from Author inspired by [1] 그러한 프로젝션 방식에는 2가지 방식이 존재합니다: 동기 및 비동기.
동기 프로젝션은 OLTP의 변경은 catch-up subscription 모델을 통해 fetch합니다. 프로젝션 엔진은 마지막 체크포인트 이후의 레코드의 추가나 업데이트를 OLTP 데이터베이스에 쿼리합니다. 이후 그러한 데이터를 시스템의 read 모델에 똑같이 반영합니다. 프로젝션 엔진은 마지막으로 처리된 레코드의 체크포인트를 저장하고 이 값은 다음 차수의 변경 레코드 탐색에 사용하게 됩니다.

Synchronous project of read models - Image from Author inspired by [1] 이러한 catch-up subscription이 동작하기 위해서는, command execution 모델이 모든 변경 레코드에 대해 체크포인트를 가지고 있어야 합니다. 또한, 스토리지 메커니즘이 체크포인트에 기반한 쿼리 실행을 지원하여야 합니다.
그 체크포인트는 관계형 데이터베이스에서는 타임스탬스 컬럼으로 구현되거나 다른 커스텀한 솔루션을 통해서 구현할 수도 있습니다.
동기 프로젝션 방법은 새로운 프로젝션을 더하는 것 뿐만 아니라 기존에 존재하던 곳에 프로젝션을 생성하는 것을 매우 쉽게 만듭니다. 후자의 사례에서, 단순히 체크포인트를 0으로 설정하면 프로젝션 엔진이 처음부터 탐색을 하며 레코드를 프로젝션 합니다.
비동기 프로젝션에서 command execution 모델은 모든 커밋된 변경을 메시지 버스로 publish합니다. 시스템의 프로젝션 엔진은 이러한 published 메시지를 subscribe하고 read 모델에 프로젝션할 수 있습니다.
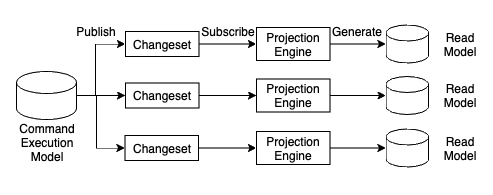
Asynchronous projection of read models - Image from Author inspired by [1] 어려운 점
비동기 프로젝션 방식의 성능과 확장성 이점에도 불구하고, 분산 컴퓨팅에서 발생하는 많은 어려운 점을 마주하게 됩니다. 만약 메시지가 순서를 벗어나거나 중복되어 처리된다면, 불일치하는 데이터가 read 모델에 프로젝트됩니다.
이 방법은 또한 새로운 프로젝션을 더하거나 기존에서 다시 생성하는 것을 어렵게 만듭니다.
이러한 이유로, 가능하면 동기 프로젝션을 구현하고 선택적으로 추가적인 비동기 프로젝션을 더하는 것을 권장합니다.
모델 분리
CQRS 아키텍쳐에서 시스템 모델의 역할은 그것의 타입에 따라 분리됩니다. 하나의 커맨드는 오직 강하게 일관된 command execution 모델 위에서 동작할 수 있습니다. 하나의 쿼리는 어떠한 시스템 상태도 직접 변경할 수 없습니다.
CQRS 기반 시스템에 대해 흔히들 많이 가지고 있는 오해는 하나의 커맨드가 오직 데이터를 변경할 수 있고 데이터는 read 모델을 통해서만 display를 위해 fetch될 수 있다고 믿는 부분입니다. 이러한 접근은 좋지 않은 UX를 만드는 불필요한 복잡성을 만들게 됩니다. 하나의 커맨드는 execution 모델로부터 처리된다면 데이터를 리턴할 수 있습니다.
사용례
CQRS 패턴은 같은 데이터를 여러 모델에서 사용하는 애플리케이션에 유용할 수 있습니다.
더욱이, CQRS는 본질적으로 이벤트 소스 도메인 모델에 기반합니다. 그 이벤트 소싱 모델은 aggregate 상태에 기반한 쿼리를 불가능하게 하나, CQRS는 상태는 쿼리 가능한 데이터베이스에 프로젝팅하여 그 부분을 가능하게 합니다.
Reference
반응형'SE Concepts' 카테고리의 다른 글
Red-Black Tree란? (1) 2021.08.22 리눅스(Linux) 기초 개념 (0) 2021.05.29 대규모 시스템에서 발생하는 데이터 처리 (feat. 패스트캠퍼스 온라인 'THE RED : 4천만 MAU를 지탱하는 서비스 설계와 데이터 처리 기술') (0) 2021.05.19 확장성 및 안정성 있는 시스템에 관하여 (feat. 패스트캠퍼스 온라인 'THE RED : 4천만 MAU를 지탱하는 서비스 설계와 데이터 처리 기술') (0) 2021.05.13 품질의 집 (House of Quality) (0) 2021.04.05 레거시를 파악하고 변경해나가기: 우선순위와 고려사항들 (0) 2021.03.18 책 '구글에서의 소프트웨어엔지니어링'의 '문화' 요약 (0) 2021.01.27 브라우저 핑거프린팅(Browser Fingerprinting)이란? (0) 2021.01.23