-
Apache Spark(아파치 스파크) Web UI 관찰하기Data 2021. 7. 1. 20:49반응형
스파크 애플리케이션의 상태를 파악하는데에 있어서 Web UI는 매우 중요한 역할을 합니다. 이번 글에서는 Spark Web UI를 살펴보며, 어떤 부분들을 고려할 수 있는지 알아보도록 하겠습니다.
살펴볼 세부적인 사항들은 아래와 같습니다:
- Jobs: 스파크 애플리케이션의 모든 job에 대한 요약 정보 제공
- Stages: 모든 jobs의 모든 stages의 현재 상태 요약 정보 제공
- Storage: persisted RDD와 DataFrames 정보 제공
- Environment: 다양한 환경 변수값
- Executors: 애플리케이션을 위해 생성된 엑서큐터 정보 제공. 메모리와 디스크 사용량과 task, shuffle 정보 등
- SQL: 애플리케이션이 Spark SQL 쿼리 실행 시 정보 제공
- Streaming: Streaming jobs 실행 시 관련 정보 제공
간단한 애플리케이션 실행하기
본격적인 Web UI 탐색 전에 아래와 같은 애플리케이션을 실행하여 UI에서 확인할 수 있도록 합니다:
df = ( spark.read.format("csv") .option("inferSchema", "true") .option("sep","\t") .option("header", "true") .load("/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed/2015_2_clickstream.tsv") )데이터브릭스 커뮤니티 에디션 환경을 사용하였고, 데이터프레임의 구조는 아래와 같습니다:

이후 repartition이 포함된 groupBy / count와 소팅을 실행합니다:
df.repartition(30).groupBy("curr_title").count().sort(F.col("count").desc()).show(100)이후 결과 데이터는 아래와 같습니다:

Jobs 탭
스파크의 애플리케이션의 action은 하나 이상의 Jobs을 생성하고 실행하게 됩니다. Jobs 탭의 랜딩페이지에서는 그러한 Jobs들의 (1) 기본 정보, (2) 이벤트 타임라인, (3) 실행되거나 완료된 Jobs 정보를 보여줍니다(위의 샘플코드 외에 일부 코드를 사전 실행하였습니다):

(1) Jobs 기본정보 에서는 아래와 같은 정보들을 보여줍니다:
- User: 현재 스파크 애플리케이션 사용자
- Total Uptime: 스파크 애플리케이션이 첫 시작 이후의 시간
- Scheduling Mode: 스파크 애플리케이션에서 여러 Jobs들이 병렬적으로 실행될 때, 어떻게 스케쥴링할지에 대한 모드
- Completed Jobs: 완료된 Jobs의 개수
(2) 이벤트 타임라인 에서는 시간 순으로 Executors와 Jobs의 상태를 그래픽으로 보여줍니다. (2)의 상단에는 한 개의 상자가 하나의 Executor, 하단에서는 하나의 상자가 하나의 Job에 해당되는 것을 볼 수 있습니다. 샘플 코드를 실행하면 (2)의 오른쪽 하단의 11:15 이후의 3개의 Jobs이 생성된 것을 확인할 수 있습니다.
(3) Completed Jobs 부분에서는 완료된 Jobs들을 Description, 제출 시간(Submitted), 소요시간(Duration), Stages 개수, Tasks 개수와 같이 나열해주고 있습니다. 실행되고 있는 Jobs이 있다면 이 부분 위에 Active Jobs에서 동일한 형태로 보여주게 됩니다. (3)의 파란색 링크를 클릭하여 각 Job의 Detail 페이지로 이동할 수 있습니다.
Job Detail 탭
개별 Job의 Detail 페이지로 이동하게 되면 아래와 같은 페이지를 볼 수 있습니다:
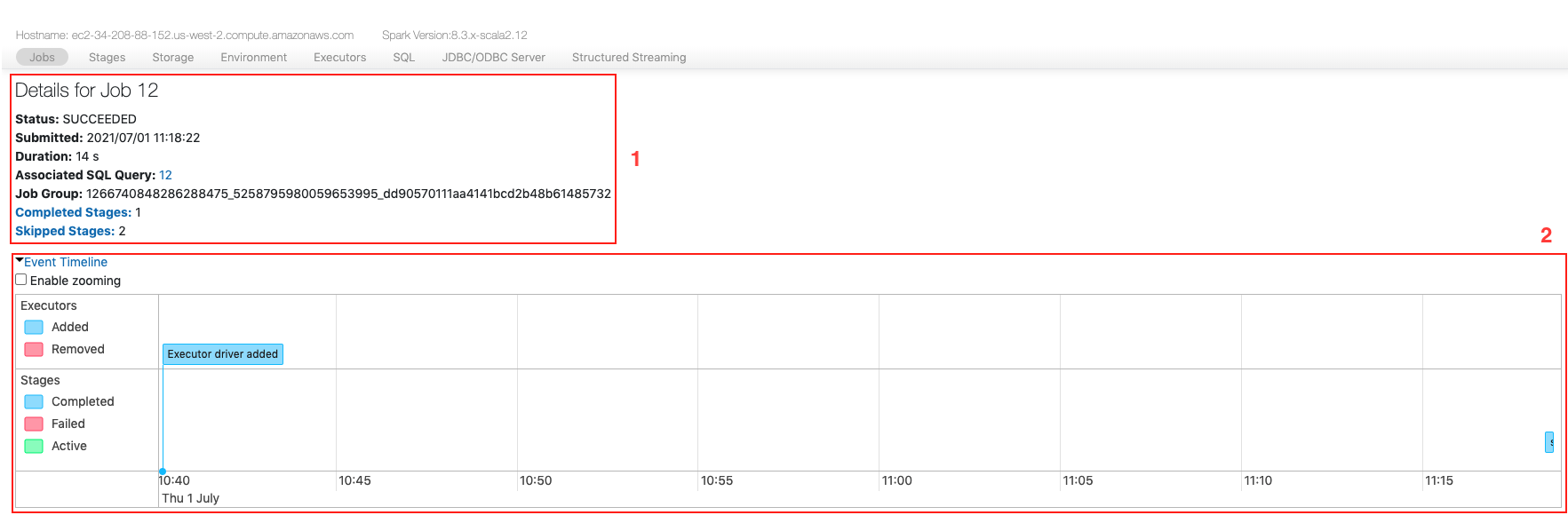
(1) Job 기본 정보 에서는 아래와 같은 사항을 확인할 수 있습니다:
- Status: Job의 상태
- Submitted: Job 제출 일시
- Duration: Job 수행 시간
- Associated SQL Query: 연관 SQL Query 번호
- Job Group: 하나의 액션은 하나 이상의 job을 생성합니다. 그러한 job들은 같은 Job Group ID로 관리되게 됩니다.
- Completed Stages: 완료 스테이지 수
- Skipped Stages: 생략된 스테이지 수. 캐시에 데이터를 사용할 수 있는 등의 이유로 재실행이 필요없어 생략된 경우.
(2) 이벤트 타임라인 에서는 이번에는 Stage별로 표시되게 됩니다.

(3) DAG 시각화 부분에서는 Job에 포함된 Stages들의 DAG(Directed acyclic graph)을 시각적으로 확인할 수 있습니다. 위에서는 16, 17 Stage가 Skipped되었고, 18 Stage만 실행된 것을 볼 수 있습니다. 각 Stage의 요소를 살펴보며 대략적인 작업흐름을 확인할 수 있습니다.

그 아래의,
(4) 완료 및 생략 Stages 부분에서는 Stage별로 축약된 정보와 함께 주요 정보들을 확인할 수 있습니다. 실행되는 Pool 이름, Stage로 이동할 수 있는 링크가 있는 Description, 제출일시, 소요시간, Tasks, 입출력 사이즈와 Shuffle Read & Write 사이즈가 그러한 정보에 포함됩니다. Task 레벨로 scale down 하기 전에 Stage 레벨에서 특정 작업이 너무 많은 Tasks를 발생시키지는 않는지, Shuffle IO가 과도하지는 않는지 등을 확인할 수 있는 중요한 부분입니다.
Description의 링크를 클릭하여 아래의 Stages 탭으로 이동할 수 있습니다.
Stages 탭
Stages 탭의 페이지에서는 Jobs 탭과 유사하게 완료 및 실행 중인 여러 Stages에 대한 정보를 확인할 수 있습니다. 또한, 개별 Stage 페이지로 이동하여서 아래와 같이 상세정보를 확인할 수 있습니다:

특징적으로 중요한 부분은 아래와 같이 병렬의 최소 단위인 Task들의 실행 이벤트 타임라인과 다양한 개별 또는 집계 메트릭을 확인할 수 있는 부분입니다. Job, Stage 레벨에서 특정 현상에 대한 전체적인 흐름을 조망했다면, 아래와 같은 개별 Task를 탐색하면서는 일부 이상치 또는 현상에 대해 더욱 세밀한 분석을 진행할 수 있습니다.


위와 같은 메트릭에서는 해당 Stage에 속하는 200개의 Tasks들에 대한 다양한 수치를 요약해서 보여주고 있습니다.
역시 개별 Task에 대한 수칟도 아래에서 확인할 수 있습니다:

Storage 탭

샘플 코드에서는 cache 또는 persist와 같은 함수를 통한 캐싱이 따로 없어서 별다른 내용이 존재하지 않는 Storage 탭입니다. 캐시가 진행되면, 그러한 데이터에 대한 정보를 전달합니다.
Environment 탭
JVM, Spark, Resource, Hadoop, System, Classpath와 같은 설정 정보들을 한눈에 확인할 수 있는 Environment 탭입니다. 스파크 운영이 기본을 넘어 다양한 것들을 시도하고자 할 때 설정을 많이 건드리게 되는데, 어떠한 설정 정보가 애플리케이션에 반영되었는지 확인할 수 있는 곳 중 하나입니다.
스파크의 옵션의 설정은 (1) 설정 파일을 통해(SPARK_HOME에 위치), (2) spark-submit 시 --conf와 같은 옵션을 통해, (3) Spark 애플리케이션 내의 SparkSession을 통해서 설정할 수 있습니다.

Executors 탭
아래와 같은 Executors 탭 역시도, 애플리케이션의 현황을 파악하기 위해 자주 살펴보게 되는 탭 중 하나입니다. 특히, 스파크는 executor-cores, executor-memory와 같이 엑서큐터 단위로 자원을 할당하기에 그러한 부분과 관련되어서 설정을 조정할 때 보게 됩니다.
그렇기에 아래의 메트릭에 있어서도 메모리와 관련된 값들이 주를 이루는 것을 볼 수 있습니다.

스파크 튜닝 시, shuffle의 IO와 함께 엑서큐터의 메모리가 주요 요소로 많이 다뤄지기에, 그러한 상황에서도 위와 같은 수치가 어떠한 부분을 나타내어 주는지 알고 있는 것은 매우 중요합니다.
SQL 탭
Spark SQL로 수행되는 작업은 아래와 같이 SQL 탭에 Query를 생성하게 됩니다. RDD 연산이 아니라 Spark SQL에 기반한 처리라면, Job, Stage, Task 정보를 통해 작업의 흐름을 파악하기는 조금 어렵습니다. 그러한 부분에서 SQL의 쿼리 플랜을 그래프로 표현하고, details 정보를 통해 각 단계의 여러 수치를 한 눈에 확인할 수 있는 이 탭은 Spark SQL의 작업흐름을 이해하는 데에 큰 도움이 됩니다.

위와 같은 Query의 Description의 링크를 통해 아래와 같은 Detail 페이지에 도달할 수 있습니다.
Scan에서부터, Exchange, Aggregate 등 쿼리 플랜에 따른 DAG을 그래프로 보여주고, +details 버튼을 클릭하여 상세한 처리 정보를 살펴볼 수 있습니다. 스파크 transformation에서 narrow와 wide를 구분하는 것과 같이, join에 따른 Shufflt의 형태는 성능에 큰 영향을 미칩니다.
그러한 join을 최적화하는데 필요한 정보는 아래의 SQL 탭에서 충분하게 얻을 수 있습니다.


JDBC/ODBC 서버 및 Streaming 탭
스파크 애플리케이션이 데이터베이스에 접근하기 위해 JDBC/ODBC 기반의 커넥션을 생성하거나, Streaming을 사용할 때 다양한 정보가 발생하는 탭들입니다. 이후 적절한 샘플과 함께 정보를 추가해보도록 하겠습니다.

Reference
[1] https://spark.apache.org/docs/latest/web-ui.html
반응형'Data' 카테고리의 다른 글
맵리듀스 처리 흐름 알아보기 (MapReduce Phases) (0) 2021.09.01 맵리듀스 작업 개선을 위한 추가적인 사항들 (2) 2021.08.28 맵리듀스란? (Hadoop MapReduce) (2) 2021.08.22 CDC(Change Data Capture)란? (0) 2021.07.16 Apache Spark(아파치 스파크) 학습을 위한 도커 환경 셋업하기 (feat. Zeppelin) (0) 2021.06.20 Databricks(데이터브릭스) Platform 아키텍쳐 및 주요개념 살펴보기 (2) 2021.06.12 Apache Spark(아파치 스파크): Adaptive Query Execution이란? (0) 2021.06.09 Apache Spark(아파치 스파크): Dynamic Partition Pruning이란? (0) 2021.06.06