-
파이썬 딕셔너리 내부구조와 관련 개념 살펴보기 (Python Dictionary Internals and relating concepts)Python 2021. 1. 4. 17:20반응형
파이썬 딕셔너리는 해쉬테이블(Hash Table)로 내부적으로 리스트를 포함(3.6 이후)하고 있으며 파이썬 언어 자체에도 많이 쓰이고 있어서(모듈 네임스페이스, 클래스 및 인스턴스 속성, 함수의 키워드 아규먼트 등 [5]), 그 내부구조를 자세히 공부해보면 다양한 중요개념들을 배울 수 있습니다. 또한, 3.6 버젼에서 내부구조가 변경되면서 키의 Ordering을 보장하였는데, 그 부분도 내부구조를 살펴보며 다룰 수 있을 것 같습니다.
이 글에서는 아래와 같은 사항을 다루고자 합니다:
- 딕셔너리는 해쉬테이블
- 왜 3.6 이후 버젼은 딕셔너리 키가 Ordering되나?
- Combined 및 Split table
- Memory 할당
- Hash collision
- Key lookup optimization (Old Version)
관련글:
딕셔너리는 해쉬테이블
딕셔너리는 키 -> 값을 매칭하는 매핑 형태의 자료구조로 collections.MutableMapping에 dict의 인터페이스가 구현되어 있습니다.
import collections # with python 3.9 a_dict = {} isinstance(a_dict, collections.MutableMapping) # 출력 True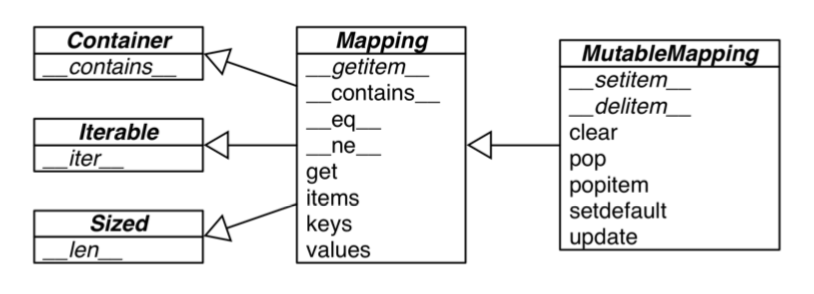
Fluent Python UML class diagram for the MutableMapping - Image from Fluent Python [5] doc distance(워드카운트, inner product 등), 데이터베이스, 컴파일러(globle variables 관리 등) 등에 고루 쓰이기에 대부분의 프로그래밍 언어에서 구현되어 있습니다. 언어마다 구현은 다르겠으나, 기본적으로는 다음과 같이 insert, delete, search의 기능을 가집니다 [3]:
a_dict = {} a_dict['a'] = 1 # insert del a_dict['a'] # delete a_dict['a'] # searchHash 함수는 '임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는' 함수입니다. 파이썬에서는 hash() 내장함수를 통해 확인해볼 수 있습니다 (객체의 tp_hash 함수를 호출).
print(hash("a")) # 출력 5675537528622735284위의 경우에는 "a"이라는 데이터를 56으로 시작하는 19자리 int에 매핑하였습니다. 키가 hash 함수(prehashing)를 통해 매핑되는 단 하나의(이상적인 상황에서) hash값으로 변환되어, 해당 hash값을 hashing 후 접근하여 값을 찾기(아래 Hash Collision이 없다고 가정)에 O(1)에 해당됩니다.
여기서 prehashing과 hashing에 대한 구분이 필요합니다 [3]:
- prehashing: hash(x) == hash(y)이면, x == y로 파이썬의 hash는 ideally prehashing임
- hashing: 커다란 key space를 한정된 크기의 m으로 줄이는데 포인트가 있음 (reduce the universe of all keys (integers) down to reasonable size m for table )
위에서 알 수 있는 부분은, 딕셔너리는 해쉬테이블이기 때문에 파이썬 딕셔너리 키가 되기 위해서는 hashable해야 한다는 사실입니다:
a_tuple = (1, 2) a_list = [1, 2] a_dict = {} # 키가 될 수 있을까? a_dict[a_tuple] = "can be a key" # 가능함 a_dict[a_list] = "cannot be a key" # TypeError: unhashable type: 'list' 발생위와 같이 unhashable한 리스트는 딕셔너리의 키가 되지 못한다는 사실을 알 수 있습니다.
728x90왜 3.6 이후 버젼은 딕셔너리 키가 Ordering되나?
3.6 버젼 이전의 딕셔너리는 아래와 같은 구조를 가집니다 [2]:

Python Dictionary Structure before 3.6 (not sure on actual location priority) - Image from Author 위와 같이, prehash, key, value 공간이 생성되는 것을 볼 수 있습니다(비어있어도).

Python Dictionary Structure after 3.6 - Image from Author 반면, 3.6 이후의 경우 array 형태의 indices(디폴트 8 사이즈)를 두고, 해당 indices에 접근 후 index를 얻어 그 index를 통해 entry에 접근하는 것을 알 수 있습니다.
3.6 이후의 구조에서 indices에서는 키를 입력한 순서대로 Ordering 되지 않지만, entries에서는 순서대로 append 되는 것을 볼 수 있습니다. 그렇기에, 이 entries를 순회하면 삽입한 순서대로 가져올 수 있게됩니다.
위의 구조를 단순화된 코드로 살펴보면 다음과 같습니다 [4]:
struct dict { long num_items; dict_entry* items; /* pointer to array */ } struct dict_entry { long hash; PyObject* key; PyObject* value; }3.6 이전 버젼이 위와 같이 dict 객체에 직접 dict_entry에 대한 포인터 items를 가지고 있는 것과 달리,
struct dict { long num_items; variable_int *sparse_array; dict_entry* compact_array; } struct dict_entry { long hash; PyObject *key; PyObject *value; }3.6 이후 버젼은 sparse_array(indices에 해당)를 가지고 있고, dict_entry가 저장되어 있는 compact_array를 가지고 있는 형태입니다.
변경 후 장점
- 메모리 사이즈 감소: 포인터 하나를 8 bytes로 잡으면, 3.6 이전 구조는 8 * 3 * 8로 192를 사용하는 반면, 변경 이후에는(위 케이스에서) 8 * 3 * 2 + 1 * 8로(entries + indices) 56을 사용합니다 (예시를 위한 가정이며, 디폴트 사이즈 딕셔너리에서 실제 메모리 할당값은 아래 'Memory 할당' 섹션을 참조하세요). 이와 같이, indices를 추가하여 keys, hash, value를 위한 메모리 할당이 좀 더 compact하게(불필요한 할당이 없이 필요한 시점에 발생하게) 되어 메모리 사용의 이점을 가집니다.
- 개선된 Caching과 GC: 좀 더 compact한 array를 가지게 되어 개선된 cache효과에 더해(TODO - 정확히 이해), 기존의 딕셔너리 구조에서는 변경(modification)이 랜덤하게 일어나 GC collection 간의 cards(또는 subsets of array - 어떤 객체가 이전 collection 이후 변경되었는지 기록?) 체킹 시 invalidate이 높은 반면에 이후의 딕셔너리 구조는 entries에 append 하는 것이 주를 이루기에 GC 성능을 올려줍니다. (Pypy)
- 위에서 언급된 것 처럼 딕셔너리 키의 순서를 보장합니다.
변경 후 단점
- 딕셔너리에서 삭제는 흔한 일은 아니지만, 딕셔너리에 다수의 삭제가 발생하면 순서를 보장하기 위해 삭제로 인해 빈곳을 방치하였다가 한 번에 몰아서 entries를 다시 compact하게 만들고 indices도 변경합니다. 이러한 경우 기존보다 성능이 조금 더 느릴 수 있습니다.
- indices 생성으로 인해 코드가 좀 더 복잡해졌을 것으로 추정됩니다(?).
Combined 및 Split table
PEP 412에서 제시되어, 최적의 경우 성능(10%)과 메모리 사용(10%)에 개선을 이루어 적용되었습니다. Combined와 Split Table이라는 명칭도 PEP 412에서 제시되었으며, 파이썬 딕셔너리의 내부구조에서 따온 이름입니다.
기존의 딕셔너리와 새롭게 제시되는 딕셔너리 모두 고정된 크기의 dict-struct와 크기 변경이 가능한 테이블로 이루어져 있습니다. 새롭게 제시되는 딕셔너리가 다른 점은 split table의 경우 keys table과 values를 따로 보관하고 combined table의 경우 기존과 유사하게 같이 보관하는 점과 dict-struct의 몇개의 필드가 추가된 점입니다.
- Split table 딕셔너리: 딕셔너리가 객체의 __slot__ 필드를 채우기 위해 생성될 때, split table 딕셔너리로 생성됩니다. keys table은 그 객체(type)에 캐싱되어서 해당 class의 모든 인스턴스가 key를 (최대)공유하도록 합니다. 해당 딕셔너리가 여러 이유로 다양해지는 경우 combined table 딕셔너리로 convert되게 됩니다.
- Combined table 딕셔너리: 명시적인 딕셔너리 생성({} 등), 모듈 딕셔너리 또는 대부분의 딕셔너리에 해당됩니다. 이러한 (native?) Combined table 딕셔너리가 split table 딕셔너리로 변경되는 일은 없습니다.
두 가지 딕셔너리에 대한 부분은 cpython 코드에도 코드레벨의 설명으로 잘 나와 있습니다:
/* The DictObject can be in one of two forms. Either: A combined table: ma_values == NULL, dk_refcnt == 1. Values are stored in the me_value field of the PyDictKeysObject. Or: A split table: ma_values != NULL, dk_refcnt >= 1 Values are stored in the ma_values array. Only string (unicode) keys are allowed. All dicts sharing same key must have same insertion order. */좀 더 직관적으로 이해되는 설명은 [2]에서 볼 수 있습니다:
# print를 위해 cpython 코드 변경하였다고 함 class B(object): b = 1 b1 = B() b2 = B() # __dict__ 객체 아직 생성 안됨 >>> b1.b 1 >>> b2.b 1 # __dict__ 생성, b1.__dict__와 b2.__dict__는 같은 PyDictKeysObject를 공유함 >>> b1.b = 3 in lookdict_split, address of PyDictObject: 0x10bc0eb40, address of PyDictKeysObject: 0x10bd8cca8, key_str: b >>> b2.b = 4 in lookdict_split, address of PyDictObject: 0x10bdbbc00, address of PyDictKeysObject: 0x10bd8cca8, key_str: b >>> b1.b in lookdict_split, address of PyDictObject: 0x10bc0eb40, address of PyDictKeysObject: 0x10bd8cca8, key_str: b 3 >>> b2.b in lookdict_split, address of PyDictObject: 0x10bdbbc00, address of PyDictKeysObject: 0x10bd8cca8, key_str: b 4 # split table에서 키 삭제 후 combined table로 변경됨. >>> b2.x = 3 in lookdict_split, address of PyDictObject: 0x10bdbbc00, address of PyDictKeysObject: 0x10bd8cca8, key_str: x >>> del b2.x in lookdict_split, address of PyDictObject: 0x10bdbbc00, address of PyDictKeysObject: 0x10bd8cca8, key_str: x # now, no more lookdict_split (split table 쪽에 박아놓은 위와 같은 print가 안나온다는 듯 함) >>> b2.b 4Memory 할당
딕셔너리에 얼마나 메모리 할당되는지 보려면, 위에서 말씀드린 indices와 entries를 먼저 나누어 살펴보면 됩니다. 아래 cpython의 코멘트에는 indices의 사이즈를 나타내는 dk_size가 어떻게 indices 인덱스 크기(타입)와 entries(dk_entries)의 사이즈에 영향을 미치는지 잘 나타내주고 있습니다.
dk_size가 증가할 수록 많은 범위의 entries의 위치를 표시해야하기에 indices의 index 크기도 증가합니다. 또한, dk_entries의 크기도 USABLE_FRACTION(dk_size)를 통해(현재 dk_size * 2/3) 만약 dk_size가 8이면, 8 * 2/3 = 5인 부분을 알 수 있습니다.
Size of indices is dk_size. Type of each index in indices is vary on dk_size: * int8 for dk_size <= 128 * int16 for 256 <= dk_size <= 2**15 * int32 for 2**16 <= dk_size <= 2**31 * int64 for 2**32 <= dk_size dk_entries is array of PyDictKeyEntry. Its size is USABLE_FRACTION(dk_size).메모리 할당은 크게 처음 딕셔너리가 생성, insertion, deletion 될 때 3가지 상황에서 발생합니다:
- 딕셔너리 생성 시: 아래 코드에서 보이듯이, PyDictKeysObject + es(indices index 크기) * size(indices array 크기) + sizeof(PyDictKeyEntry) * usable(USABLE_FRACTION(indices array 크기)로 구한값)이 할당되는 것을 볼 수 있습니다.
dk = PyObject_MALLOC(sizeof(PyDictKeysObject) + es * size + sizeof(PyDictKeyEntry) * usable);- insertion: 만약 dk_usable이 0보다 작거나 같으면 insertion_resize를 호출하는데, insertion_resize 내부에서는 GROWTH_RATE 함수를 사용하여 ma_used(현재 사용하고 있는 사이즈) * 3보다 작은 최대 2의 배수값을 새로운 (크기를 늘린) indices size로 하여 생성하고, 기존 key, hash, value 값을 하나씩 복사해줍니다.
# dk_usable 확인 부분 if (mp->ma_keys->dk_usable <= 0) { /* Need to resize. */ if (insertion_resize(mp) < 0) goto Fail; } # insertion_resize static int insertion_resize(PyDictObject *mp) { return dictresize(mp, GROWTH_RATE(mp)); } # GROWTH_RATE #define GROWTH_RATE(d) ((d)->ma_used*3)- deletion: item 삭제 시에는 insertion과 같이 resize가 일어나지 않습니다. 만약 큰 딕셔너리에서 계속 삭제만 된다면, 해당 딕셔너리는 처음과 같은 메모리를 차지하고 있게 됩니다 (아마 삭제를 실행하는 경우 다시 추가가 주로 있고, 그로 인해 너무 빈번한 resizing을 피하기 위해서).
(TODO: 파이썬 메모리 사용량 코드 추가)
Hash collision
Hash 테이블에서는 두 개의 키가 같은 해쉬 값을 가질 때 어떻게 처리할지 결정하는 부분이 중요합니다. 한 가지 주요 방법은 Chaining [3]이나 파이썬은, 전자가 키 별로 메모리 할당이 필요하고(느림) 캐쉬 locality 문제도 있어서, 다른 방법인 Open Addressing을 사용합니다.
Open Addressing의 가장 흔한 방법은 linear probing입니다. slot i가 자리가 없다면, i+1를, 또 자리가 없다면 i+2를 탐색하며 자리가 있는 곳을 찾으면 키를 넣습니다. 파이썬을 사용하는 프로그램에서 주로 int를 키로 많이 사용하기 때문에, 이러한 linear probing을 사용하면 탐색 시 매우 느리기에 파이썬은 아래와 같은 좀 더 복잡한 방법을 사용합니다 (상세 PERTURB_SHIFT):
#define PERTURB_SHIFT 5 j = ((5*j) + 1) mod 2**i #0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0 [and here it's repeating] perturb >>= PERTURB_SHIFT; j = (5*j) + 1 + perturb; # use j % 2**i as the next table index;Key lookup optimization (Old Version)
파이썬 딕셔너리의 최적화와 관련된 또 다른 부분은 string 이외의 데이터가 요청되기 전까지 string 전용 함수를 사용하는 부분입니다. PyDictObject는 ma_lookup(3.9.1에서 dk_lookup)이라는 필드를 가지고 있는데, 이것은 key look up에 사용되는 함수에 대한 포인터 입니다:
struct PyDictObject { ... PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash); };딕셔너리 구현체는 (dict->ma_lookup)(dict, key, hash) 같은 형태를 호출하여 key를 얻습니다: key는 Key를 나타내는 객체에 대한 포인터이고 hash는 key를 통해 얻어진 해쉬값입니다.
ma_lookup은 기본적으로 lookdict_string으로 세팅되어 있습니다. 해당 함수는 두 키 모두 string으로 가정하기에 몇 가지 shortcut을 이용합니다. string-to-string 비교는 에러를 발생시키지 않아서 에러 체킹이 스킵될 수 있습니다. 다른 한 가지로는 객체에 여러가지 비교연산이 필요 없는 부분입니다(<, >, <=, >= 등).
nonstring이 입력되게 되면 ma_lookup에 lookdict로 바뀝니다.
Reference
[1] StackOverflow - How are Python's Built In Dictionaries Implemented?
[2] Github - CPython Internals Dict
[3] MITOpenCourseWare - 8. Hashing with Chaining
[4] Faster, more memory efficient and more ordered dictionaries on PyPy
[5] Fluent Python
[6] collections - Container Datatypes
[7] PEP 412 -- Key-Sharing-Dictionary
[8] PEP 509 -- Add a private version to dict
[9] PEP 468 -- Preserving the order of **kwargs in a function.
[10] PEP 520 -- Preserving Class Attribute Definition Order
[11] PyCon 2010: The Might Dictionary - Brandon Rhodes
[12] PyCon 2017: The Dictionary Even Mightier - Brandon Rhodes
[13] PyCon 2017: Modern Python Dictionaries A confluence of a dozen great ideas - Raymond Hettinger
[14] Python dictionary implementation
[15] Beautiful Code - Ch 18. Python’s Dictionary Implementation: Being All Things to All People
반응형'Python' 카테고리의 다른 글
프로그래밍 언어와 파이썬 (2) 2021.05.19 파이썬 int 내부구조 (Python int Internals) (0) 2021.02.22 파이썬 리스트 내부구조 (Python List Internals) (0) 2021.02.13 파이썬 클래스 내부구조 (Python Class Internals) (0) 2021.01.25 파이썬으로 구글 시트 생성 후 다른 유저에게 공유하기 (0) 2021.01.16 파이썬 튜플 내부구조 (Python Tuple Internals) (0) 2021.01.12 파이썬 딕셔너리 루프 - 파이썬 딕셔너리 순회하기 (Python Dictionary Iteration) (0) 2021.01.01 코딩초보 파이썬(Python) 공부법, 공부자료 (파이썬입문, 파이썬강좌) (0) 2020.11.23